资源下载
资源下载

0
这种情况发生在使用Dropout时,因为训练和测试时的行为是不同的。 在训练时,一定比例的功能被设置为零(在你的情况下是50%,因为你使用的Dropout(0.5))。 在测试时,所有功能都被使用(并适当地缩放)。因此,测试时的模型鲁棒性更好,可以导致更高的测试准确度。
收藏
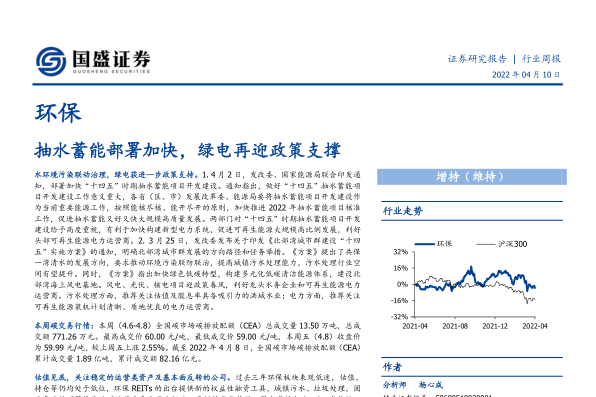
我正在尝试使用深度学习从约会网站的15个用户属性中预测收入。 我得到的结果相当奇怪,与训练数据相比,验证数据具有更高的准确性和更低的损失。不同大小的隐藏层结果是一致的。 这是我的模型:
for hl1 in [250, 200, 150, 100, 75, 50, 25, 15, 10, 7]:
def baseline_model():
model = Sequential()
model.add(Dense(hl1, input_dim=299, kernel_initializer='normal', activation='relu', kernel_regularizer=regularizers.l1_l2(0.001)))
model.add(Dropout(0.5, seed=seed))
model.add(Dense(3, kernel_initializer='normal', activation='sigmoid'))
model.compile(loss='categorical_crossentropy', optimizer='adamax', metrics=['accuracy'])
return model
history_logs = LossHistory()
model = baseline_model()
history = model.fit(X, Y, validation_split=0.3, shuffle=False, epochs=50, batch_size=10, verbose=2, callbacks=[history_logs])
这是准确性和损失的一个图例:

 我试图消除正则化和dropout,结果以过度拟合告终(训练acc:〜85%)。我甚至尝试过大幅度降低学习率,但取得了相似的结果。
有没有人看到过类似的结果?
我试图消除正则化和dropout,结果以过度拟合告终(训练acc:〜85%)。我甚至尝试过大幅度降低学习率,但取得了相似的结果。
有没有人看到过类似的结果?
这种情况发生在使用Dropout时,因为训练和测试时的行为是不同的。 在训练时,一定比例的功能被设置为零(在你的情况下是50%,因为你使用的Dropout(0.5))。 在测试时,所有功能都被使用(并适当地缩放)。因此,测试时的模型鲁棒性更好,可以导致更高的测试准确度。