资源下载
资源下载

0
有
首先我们可以引入额外的专家知识将未标记样本转化为标记样本参与训练模型,这是基于主动学习的方法。但是若不获得额外信息,我们也可以利用未标记样本提高模型的泛化性能。
未标记样本
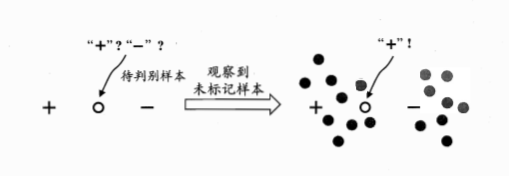
未标记样本就是不直接含有标记信息的样本。但是它们与标记样本是同样的数据源独立同分布采样而来。因此它们所包含的关于数据分布的信息对于建立模型大有裨益,如下图所示,图中只有一个正例和一个反例,则待判别样本恰好位于两者正中间,大体上只能随机猜测;若能观察到图中的未标记样本,则将有把握判别为正例。
收藏