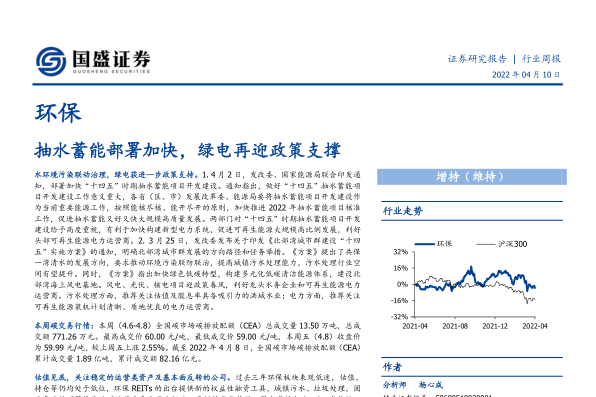
资源下载
资源下载

从以下几个方面对SqueezeNet进行介绍
- 架构设计策略
- Fire Module
- SqueezeNet体系结构
- SqueezeNet的评估
1. 架构设计策略
策略1.用1×1滤波器替换3×3滤波器
- 给定一定数量的卷积滤波器的预算,我们可以选择将大部分滤波器设置为1×1,因为1×1滤波器的参数比3×3滤波器少9倍。
策略2.减少3×3滤波器的输入通道数
- 考虑一个完全由3×3滤波器组成的卷积层。 该层中的参数总数为:
- (输入通道数)×(滤波器数)×(3×3)
- 我们可以使用压缩层将输入通道的数量减少到3×3滤波器,这将在下一部分中提到。
策略3.在网络后进行下采样,以使卷积层具有较大的激活图
- 直观上,大的激活图(由于延迟的下采样)可以得到更高的分类精度。
总结
- 策略1和策略2是在保持准确性的同时,有效地减少CNN中的参数数量。
- 策略3是在有限参数预算上的最大化准确性。
2. Fire Module

Fire Module包括:压缩卷积层(仅具有1×1滤波器),馈入1×1和3×3卷积滤波器混合存在的扩展层。
Fire模块中有三个超参数:s1×1,e1×1和e3×3。
- s1×1:压缩层中的1×1的数量。
- e1×1和e3×3:扩展层中1×1和3×3的数量。
当我们使用Fire模块时,我们设置s1×1小于(e1×1 + e3×3),因此压缩层帮助将输入通道的数量限制为3×3滤波器,如上一节中的策略2所示 。
对我来说,它很像 Inception模块。
3. SqueezeNet体系结构


SqueezeNet(左):从独立的卷积层(conv1)开始,紧跟着是8个Fire模块(fire2-9),最后是一个conv层(conv10)。
从网络的开始到结束,每个Fire模块的滤波器数量逐渐增加。
在层conv1,fire4,fire8和conv10之后执行步长为2的最大池化。
带简单旁路的SqueezeNet(中)和带复杂旁路的SqueezeNet(右):旁路的使用受ResNet启发。
4. SqueezeNet的评估
4.1 比较SqueezeNet的建模压缩方法

与AlexNet相比,借助SqueezeNet,我们将模型尺寸减少了50倍,同时达到甚至超过AlexNet的top-1和top-5精度。
模型尺寸的减小远高于SVD,网络剪枝和深度压缩。
通过使用8位量化的深度压缩,SqueezeNet产生了0.66 MB的模型(比32位AlexNet小363倍),其精度与AlexNet相当。 此外,在SqueezeNet上应用具有6位量化和33%稀疏性的深度压缩,这是一个0.47MB的模型(比32位AlexNet小510倍),具有相同的精度。 SqueezeNet确实可以压缩。
4.2 超参数

压缩比(SR)(左):压缩层中的滤波器数量与扩展层中的滤波器数量之间的比率。
将SR增加到0.125以上可以进一步将ImageNet top-5的准确性从4.8MB模型的80.3%(即AlexNet级别)提高到19MB模型的86.0%。 在SR = 0.75(一个19MB模型)的情况下,准确度稳定在86.0%,如果设置SR = 1.0,则进一步增加了模型大小,而不提高准确性。
3×3滤波器的占比(右:使用50%3×3滤波器的前5个精度稳定在85.6%,进一步增加3×3滤波器的占比会使模型尺寸更大,但对ImageNet的准确性没有改善。
4.3 SqueezeNet变体

复杂和简单的旁路连接都比普通的SqueezeNet架构精度高。
有趣的是,与复杂旁路相比,简单旁路可实现更高的准确性。
添加简单的旁路连接后,在不增加模型尺寸的情况下,top-1精度提高了2.9个百分点,top-5精度提高了2.2个百分点。
通过使用Fire Module,可以在保持预测准确性的同时减小模型大小。
参考来源https://towardsdatascience.com/review-squeezenet-image-classification-e7414825581a