 资源下载
资源下载



基于飞桨复现SRGAN模型-一种用于图像超分辨率的生成对抗网络

文件列表(压缩包大小 12.88K)
免费
概述
基于飞桨复现SRGAN模型,对图像进行超分辨率重构
一种用于图像超分辨率(SR)的生成对抗网络(GAN),能够推断4倍放大因子的照片般逼真的自然图像。
- 文章来源:2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
- 下载链接:Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
前言
在GAN领域中,超分辨率复原一直是计算机视觉领域一个十分热门的研究方向,在商业上也有着很大的用武之地,随着2014年lan J. Ggoodflew那篇惊世骇俗的GAN发表出来,GAN伴随着CNN一起,可谓是乘风破浪,衍生出来琳琅满目的各种应用。
SRGAN,2017年CVPR中备受瞩目的超分辨率论文,把超分辨率的效果带到了一个新的高度,而2017年超分大赛NTIRE的冠军EDSR也是基于SRGAN的变体。对于此篇论文,据说这是第一篇将GAN网络应用到超分领域的论文,很多涉及到图像超分辨率重构的技术博客都有提到过它。其实它的难度并不大,但它的重构思想从学习的角度来说,是能够让我们有很大的收获的。
图像的超分辨率重构技术(Super-Resolution)指的是将给定的低分辨率图像通过算法恢复成相应的高分辨率图像,其主要分为两个大类:一类是使用单张低分辨率图像进行高分辨率图像的重建,一类是使用同一场景的多张低分辨率图像进行高分辨率图像的重建。此篇文章使用的是基于深度学习中的GAN网络对单张图像进行操作的超分辨率重构方法
超分辨重构和去噪、去网格、去模糊等问题是类似的。对于一张低分辨图像,可能会有多张高分辨图像与之对应,因此通常在求解高分辨率图像时会加一个先验信息进行规范化约束。在传统的方法中,通常会通过加入一些先验信息来恢复高分辨率图像,如,插值法、稀疏学习、还有基于回归方法的随机森林等。而基于深度学习的SR方法,则是通过神经网络直接进行从低分辨图像到高分辨图像的端到端的学习。
SRGAN不同于普通的GAN是通过噪声来生成一个真实图片,SRGAN的目的在于将一个低分辨率的图片转化为一个高分辨率的图片。利用感知损失(perceptual loss)和对抗损失(adversarial loss)来提升恢复出的图片的真实感。感知损失是利用卷积神经网络(VGG19)提取出的特征,通过比较生成图片的特征和与目标图片之间的特征差别,使生成图片和目标图片在语义和风格上更相似。简单来说通俗来讲,所要完成的工作就是:通过G网络使低分辨率的图像重建出一张高分辨率的图像,再由D网络判断拿到的生成图与原图之间的差别,当G网络的生成图能够很好的骗过D网络,使之相信此生成图即为原数据集中的图像之一,那么超分辨率重构的网络就实现了。
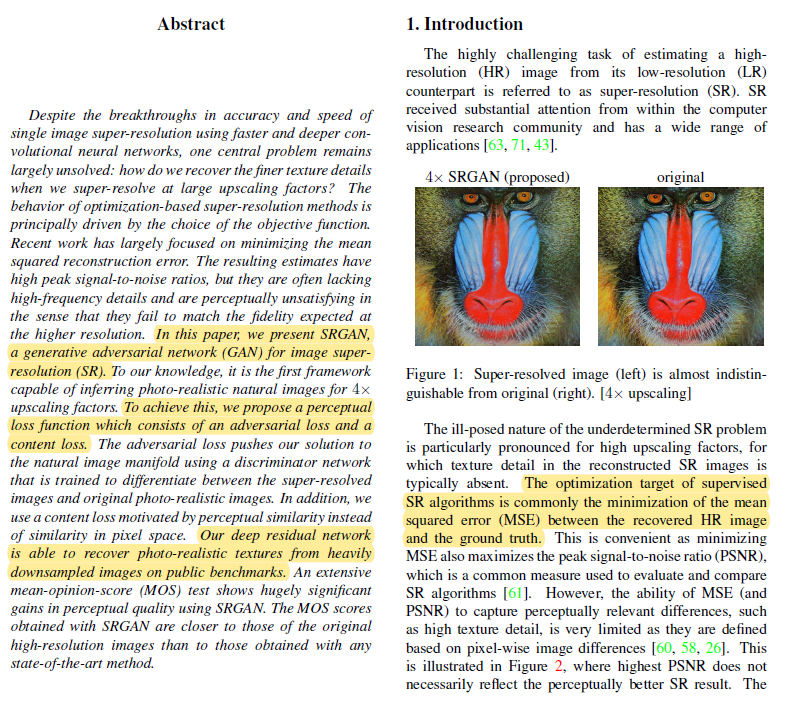
- 作者认为,这篇文章之前,主要重建工作都集中在最小化均方重建误差上,这篇文章是生成式对抗网络第一次应用于4倍下采样图像的超分辨重建工作。。由此得到的估计值具有较高的峰值信噪比,但它们通常缺少高频细节,并且在感觉上不令人满意,因为它们无法匹配在更高分辨率下预期的保真度。
- 为了达到能够在4倍放大因子下推断照片真实自然图像的目的,作者提出了一个由对抗性损失和内容损失组成的感知损失函数,该网络使用经过训练的VGG19网络来区分超分辨率图像和原始照片真实感图像,此外,在像素空间中,又使用了一个由感知相似度驱动的内容丢失,而不是像素空间中的相似性。作者的深度残差网络能够在公共基准上从大量减少采样的图像中恢复照片真实感纹理。用SRGAN获得的MOS分数比用任何最先进的方法得到的结果更接近原始高分辨率图像。
网络结构
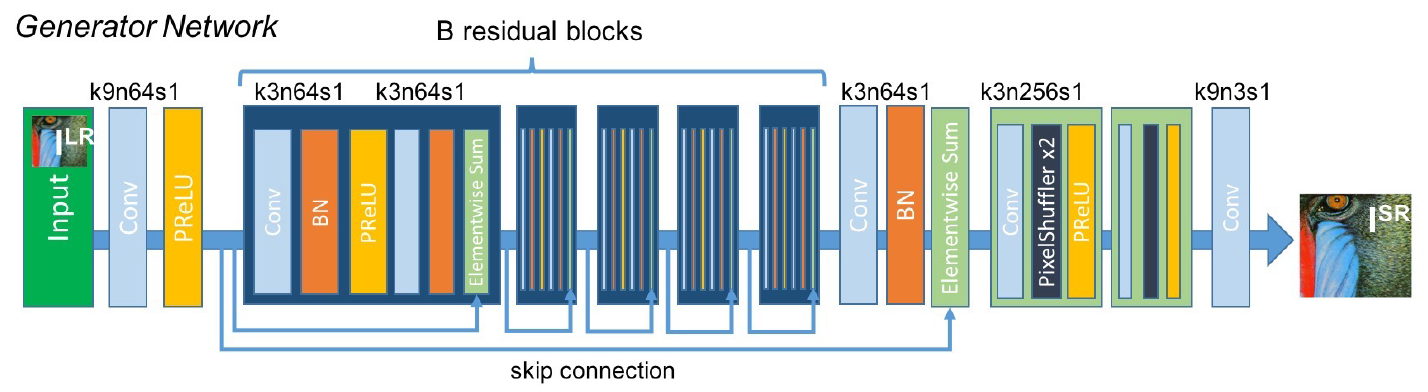
SRGAN网络结构如下图(SRGAN还是用SRRESNET来进行超分工作 但增加了一个对抗网络来判断生成的图片是原图还是超分出来的图):
生成器网络的体系结构,每个卷积层对应的内核大小(k)、特征映射数(n)和步长(s)。
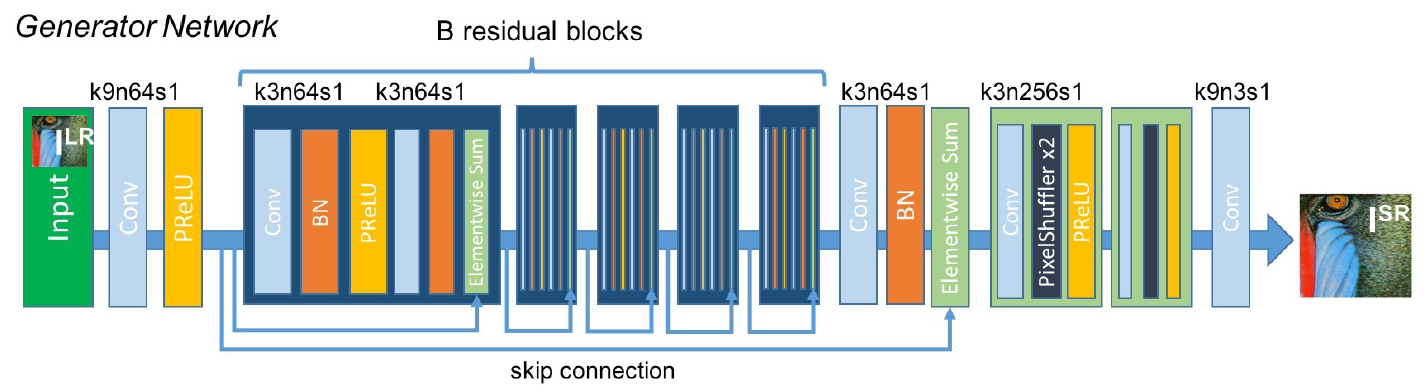
在生成网络中,输入是一个低分辨率的图像,先进行卷积、relu,又为了能够更好的网络架构和提取特征,还引入了残差模块,最后再通过特征提取、特征重构,得到输出结果。
def SRGAN_g(t_image): # Input-Conv-Relu n = fluid.layers.conv2d(input=t_image, num_filters=64, filter_size=3, stride=1, padding='SAME', name='n64s1/c', data_format='NCHW') # print('conv0', n.shape) n = fluid.layers.batch_norm(n, momentum=0.99, epsilon=0.001) n = fluid.layers.relu(n, name=None) temp = n # B residual blocks # Conv-BN-Relu-Conv-BN-Elementwise_add for i in range(16): nn = fluid.layers.conv2d(input=n, num_filters=64, filter_size=3, stride=1, padding='SAME', name='n64s1/c1/%s' % i, data_format='NCHW') nn = fluid.layers.batch_norm(nn, momentum=0.99, epsilon=0.001, name='n64s1/b1/%s' % i) nn = fluid.layers.relu(nn, name=None) log = 'conv%2d' % (i+1) # print(log, nn.shape) nn = fluid.layers.conv2d(input=nn, num_filters=64, filter_size=3, stride=1, padding='SAME', name='n64s1/c2/%s' % i, data_format='NCHW') nn = fluid.layers.batch_norm(nn, momentum=0.99, epsilon=0.001, name='n64s1/b2/%s' % i) nn = fluid.layers.elementwise_add(n, nn, act=None, name='b_residual_add/%s' % i) n = nn n = fluid.layers.conv2d(input=n, num_filters=64, filter_size=3, stride=1, padding='SAME', name='n64s1/c/m', data_format='NCHW') n = fluid.layers.batch_norm(n, momentum=0.99, epsilon=0.001, name='n64s1/b2/%s' % i) n = fluid.layers.elementwise_add(n, temp, act=None, name='add3') # print('conv17', n.shape) # B residual blacks end # Conv-Pixel_shuffle-Conv-Pixel_shuffle-Conv n = fluid.layers.conv2d(input=n, num_filters=256, filter_size=3, stride=1, padding='SAME', name='n256s1/1', data_format='NCHW') n = fluid.layers.pixel_shuffle(n, upscale_factor=2) n = fluid.layers.relu(n, name=None) # print('conv18', n.shape) n = fluid.layers.conv2d(input=n, num_filters=256, filter_size=3, stride=1, padding='SAME', name='n256s1/2', data_format='NCHW') n = fluid.layers.pixel_shuffle(n, upscale_factor=2) n = fluid.layers.relu(n, name=None) # print('conv19', n.shape) n = fluid.layers.conv2d(input=n, num_filters=3, filter_size=1, stride=1, padding='SAME', name='out', data_format='NCHW') n = fluid.layers.tanh(n, name=None) # print('conv20', n.shape) return n
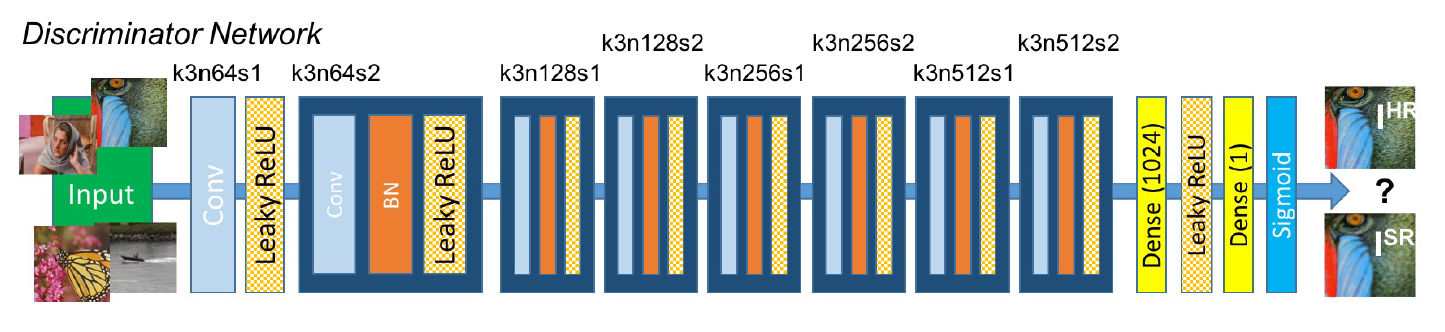
鉴别器网络的体系结构,每个卷积层对应的内核大小(k)、特征映射数(n)和步长(s)。
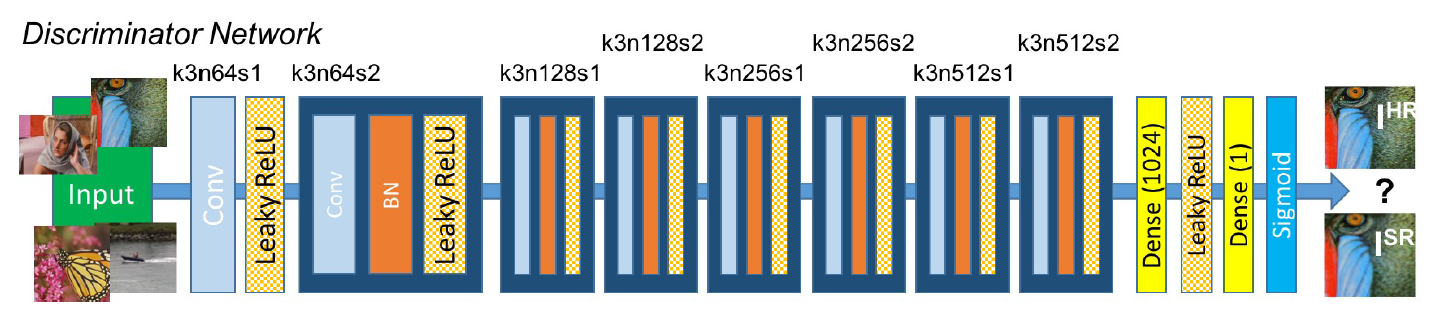
- 在鉴别网络中,都是些常规的 Cnov、BN、Leaky_Relu、fc,为了对生成网络生成的图像数据进行判断,判断其是否是真实的训练数据中的数据。
def SRGAN_d(input_images):
# Conv-Leaky_Relu
net_h0 = fluid.layers.conv2d(input=input_images, num_filters=64, filter_size=4, stride=2, padding='SAME', name='h0/c', data_format='NCHW')
net_h0 = fluid.layers.leaky_relu(net_h0, alpha=0.2, name=None)
# h1 Cnov-BN-Leaky_Relu
net_h1 = fluid.layers.conv2d(input=net_h0, num_filters=128, filter_size=4, stride=2, padding='SAME', name='h1/c', data_format='NCHW')
net_h1 = fluid.layers.batch_norm(net_h1, momentum=0.99, epsilon=0.001, name='h1/bn')
net_h1 = fluid.layers.leaky_relu(net_h1, alpha=0.2, name=None)
# h2 Cnov-BN-Leaky_Relu
net_h2 = fluid.layers.conv2d(input=net_h1, num_filters=256, filter_size=4, stride=2, padding='SAME', name='h2/c', data_format='NCHW')
net_h2 = fluid.layers.batch_norm(net_h2, momentum=0.99, epsilon=0.001, name='h2/bn')
net_h2 = fluid.layers.leaky_relu(net_h2, alpha=0.2, name=None)
# h3 Cnov-BN-Leaky_Relu
net_h3 = fluid.layers.conv2d(input=net_h2, num_filters=512, filter_size=4, stride=2, padding='SAME', name='h3/c', data_format='NCHW')
net_h3 = fluid.layers.batch_norm(net_h3, momentum=0.99, epsilon=0.001, name='h3/bn')
net_h3 = fluid.layers.leaky_relu(net_h3, alpha=0.2, name=None)
# h4 Cnov-BN-Leaky_Relu
net_h4 = fluid.layers.conv2d(input=net_h3, num_filters=1024, filter_size=4, stride=2, padding='SAME', name='h4/c', data_format='NCHW')
net_h4 = fluid.layers.batch_norm(net_h4, momentum=0.99, epsilon=0.001, name='h4/bn')
net_h4 = fluid.layers.leaky_relu(net_h4, alpha=0.2, name=None)
# h5 Cnov-BN-Leaky_Relu
net_h5 = fluid.layers.conv2d(input=net_h4, num_filters=2048, filter_size=4, stride=2, padding='SAME', name='h5/c', data_format='NCHW')
net_h5 = fluid.layers.batch_norm(net_h5, momentum=0.99, epsilon=0.001, name='h5/bn')
net_h5 = fluid.layers.leaky_relu(net_h5, alpha=0.2, name=None)
# h6 Cnov-BN-Leaky_Relu
net_h6 = fluid.layers.conv2d(input=net_h5, num_filters=1024, filter_size=4, stride=2, padding='SAME', name='h6/c', data_format='NCHW')
net_h6 = fluid.layers.batch_norm(net_h6, momentum=0.99, epsilon=0.001, name='h6/bn')
net_h6 = fluid.layers.leaky_relu(net_h6, alpha=0.2, name=None)
# h7 Cnov-BN-Leaky_Relu
net_h7 = fluid.layers.conv2d(input=net_h6, num_filters=512, filter_size=4, stride=2, padding='SAME', name='h7/c', data_format='NCHW')
net_h7 = fluid.layers.batch_norm(net_h7, momentum=0.99, epsilon=0.001, name='h7/bn')
net_h7 = fluid.layers.leaky_relu(net_h7, alpha=0.2, name=None)
#修改原论文网络
net = fluid.layers.conv2d(input=net_h7, num_filters=128, filter_size=1, stride=1, padding='SAME', name='res/c', data_format='NCHW')
net = fluid.layers.batch_norm(net, momentum=0.99, epsilon=0.001, name='res/bn')
net = fluid.layers.leaky_relu(net, alpha=0.2, name=None)
net = fluid.layers.conv2d(input=net_h7, num_filters=128, filter_size=3, stride=1, padding='SAME', name='res/c2', data_format='NCHW')
net = fluid.layers.batch_norm(net, momentum=0.99, epsilon=0.001, name='res/bn2')
net = fluid.layers.leaky_relu(net, alpha=0.2, name=None)
net = fluid.layers.conv2d(input=net_h7, num_filters=512, filter_size=3, stride=1, padding='SAME', name='res/c3', data_format='NCHW')
net = fluid.layers.batch_norm(net, momentum=0.99, epsilon=0.001, name='res/bn3')
net = fluid.layers.leaky_relu(net, alpha=0.2, name=None)
net_h8 = fluid.layers.elementwise_add(net_h7, net, act=None, name='res/add')
net_h8 = fluid.layers.leaky_relu(net_h8, alpha=0.2, name=None)
#net_ho = fluid.layers.flatten(net_h8, axis=0, name='ho/flatten')
net_ho = fluid.layers.fc(input=net_h8, size=1024, name='ho/fc')
net_ho = fluid.layers.leaky_relu(net_ho, alpha=0.2, name=None)
net_ho = fluid.layers.fc(input=net_h8, size=1, name='ho/fc2')
# return
# logits = net_ho
net_ho = fluid.layers.sigmoid(net_ho, name=None)
return net_ho # , logits
- 为了尽可能地训练出模型的效果,在本项目中直接使用了飞桨的 VGG19网络实现代码,并使用飞桨官方提供的在ImageNet上预训练好的VGG预训练模型,该模型在ImageNet-2012验证集合上的top-1和top-5精度分别为72.56%、90.93%,性能优越。
- 在本项目的训练过程中能够起到精准提取图像特征信息的作用,缩小生成图与原图的差距,提升生成网络的生成图像效果。
def conv_block(input, num_filter, groups, name=None):
conv = input
for i in range(groups):
conv = fluid.layers.conv2d(
input=conv,
num_filters=num_filter,
filter_size=3,
stride=1,
padding=1,
act='relu',
param_attr=fluid.param_attr.ParamAttr(
name=name + str(i + 1) + "_weights"),
bias_attr=False)
return fluid.layers.pool2d(
input=conv, pool_size=2, pool_type='max', pool_stride=2)
def vgg19(input, class_dim=1000):
# VGG_MEAN = [123.68, 103.939, 116.779]
# """ input layer """
# net_in = (input + 1) * 127.5
# red, green, blue = fluid.layers.split(net_in, num_or_sections=3, dim=1)
# net_in = fluid.layers.concat(input=[red-VGG_MEAN[0], green-VGG_MEAN[1], blue-VGG_MEAN[2]], axis=0)
layers = 19
vgg_spec = {
11: ([1, 1, 2, 2, 2]),
13: ([2, 2, 2, 2, 2]),
16: ([2, 2, 3, 3, 3]),
19: ([2, 2, 4, 4, 4])
}
assert layers in vgg_spec.keys(), \
"supported layers are {} but input layer is {}".format(vgg_spec.keys(), layers)
nums = vgg_spec[layers]
conv1 = conv_block(input, 64, nums[0], name="vgg19_conv1_")
conv2 = conv_block(conv1, 128, nums[1], name="vgg19_conv2_")
conv3 = conv_block(conv2, 256, nums[2], name="vgg19_conv3_")
conv4 = conv_block(conv3, 512, nums[3], name="vgg19_conv4_")
conv5 = conv_block(conv4, 512, nums[4], name="vgg19_conv5_")
fc_dim = 4096
fc_name = ["fc6", "fc7", "fc8"]
fc1 = fluid.layers.fc(
input=conv5,
size=fc_dim,
act='relu',
param_attr=fluid.param_attr.ParamAttr(
name=fc_name[0] + "_weights"),
bias_attr=fluid.param_attr.ParamAttr(name=fc_name[0] + "_offset"))
fc1 = fluid.layers.dropout(x=fc1, dropout_prob=0.5)
fc2 = fluid.layers.fc(
input=fc1,
size=fc_dim,
act='relu',
param_attr=fluid.param_attr.ParamAttr(
name=fc_name[1] + "_weights"),
bias_attr=fluid.param_attr.ParamAttr(name=fc_name[1] + "_offset"))
fc2 = fluid.layers.dropout(x=fc2, dropout_prob=0.5)
out = fluid.layers.fc(
input=fc2,
size=class_dim,
param_attr=fluid.param_attr.ParamAttr(
name=fc_name[2] + "_weights"),
bias_attr=fluid.param_attr.ParamAttr(name=fc_name[2] + "_offset"))
return out, conv5
损失函数
论文中还给出了生成器和判别器的损失函数的形式:
生成器的损失函数
$\hat{\theta }G = argmin{\theta_G}\frac{1}{N}\sum_{n=1}^{N}l^{SR}(G_{\theta_G}(I_n^{LR}),I_n^{HR})$
其中,$l^{SR}()$为本文所提出的感知损失函数,$l^{SR}=l_{VGG}^{SR}+10^{-3}l_{Gen}^{SR}$ 。
内容损失 $l_{VGG}^{SR} = \frac{1}{WH} \sum_{x=1}^W\sum_{y=1}^H (\phi (I^{HR} ){x,y} - \phi (G{\theta {G} } (I^{LR} )){x,y})^2 $; 训练网络时使用均方差损失可以获得较高的峰值信噪比,一般的超分辨率重建方法中,内容损失都选择使用生成图像和目标图像的均方差损失(MSELoss),但是使用均方差损失恢复的图像会丢失很多高频细节。因此,本文先将生成图像和目标图像分别输入到VGG网络中,然后对他们经过VGG后得到的feature map求欧式距离,并将其作为VGG loss。
对抗损失 $l_{Gen}^{SR} = \sum_{n=1}^N (-log D_{\theta {D} }(G{\theta G}(I^{LR})))$; 为了避免当判别器训练较好时生成器出现梯度消失,本文将生成器的损失函数$l{Gen}^{SR}=\sum_{n=1}^N log(1-D_{\theta {D} }(G{\theta _G}(I^{LR})))$进行了修改。
判别器的损失函数为:
$ \hat{\theta } {D} = E{p(I^{HR} )} [log D_{\theta {D} }(I^{LR} )]+ E{q(I^{LR} )} [log (1-D_{\theta {D} }(G{\theta _G}(I^{LR} )) )]$ 与普通的生成对抗网络判别器的的损失函数类似。
训练策略
先对 G 网络进行预训练,再将 G 和 D 网络一起训练
# init
t_image = fluid.layers.data(name='t_image',shape=[96, 96, 3],dtype='float32')
t_target_image = fluid.layers.data(name='t_target_image',shape=[384, 384, 3],dtype='float32')
vgg19_input = fluid.layers.data(name='vgg19_input',shape=[224, 224, 3],dtype='float32')
step_num = int(len(train_hr_imgs) / batch_size)
# initialize G
for epoch in range(0, n_epoch_init + 1):
epoch_time = time.time()
np.random.shuffle(train_hr_imgs)
# real
sample_imgs_384 = random_crop(train_hr_imgs, 384)
sample_imgs_standardized_384 = standardized(sample_imgs_384)
# input
sample_imgs_96 = im_resize(sample_imgs_384,96,96)
sample_imgs_standardized_96 = standardized(sample_imgs_96)
# vgg19
sample_imgs_224 = im_resize(sample_imgs_384,224,224)
sample_imgs_standardized_224 = standardized(sample_imgs_224)
# loss
total_mse_loss, n_iter = 0, 0
for i in tqdm.tqdm(range(step_num)):
step_time = time.time()
imgs_384 = sample_imgs_standardized_384[i * batch_size:(i + 1) * batch_size]
imgs_384 = np.array(imgs_384, dtype='float32')
imgs_96 = sample_imgs_standardized_96[i * batch_size:(i + 1) * batch_size]
imgs_96 = np.array(imgs_96, dtype='float32')
# vgg19 data
imgs_224 = sample_imgs_standardized_224[i * batch_size:(i + 1) * batch_size]
imgs_224 = np.array(imgs_224, dtype='float32')
# print(imgs_384.shape)
# print(imgs_96.shape)
# print(imgs_224.shape)
# update G
mse_loss_n = exe.run(SRGAN_g_program,
feed={'t_image': imgs_96, 't_target_image': imgs_384, 'vgg19_input':imgs_224},
fetch_list=[mse_loss])[0]
#print(mse_loss_n)
#print("Epoch [%2d/%2d] %4d time: %4.4fs, mse: %.8f " % (epoch, n_epoch_init, n_iter, time.time() - step_time, mse_loss_n))
total_mse_loss += mse_loss_n
n_iter += 1
log = "[*] Epoch_init: [%2d/%2d] time: %4.4fs, mse: %.8f" % (epoch, n_epoch_init, time.time() - epoch_time, total_mse_loss / n_iter)
print(log)
if (epoch != 0) and (epoch % 10 == 0):
out = exe.run(SRGAN_g_program,
feed={'t_image': imgs_96, 't_target_image': imgs_384, 'vgg19_input':imgs_224},
fetch_list=[test_im])[0][0]
# generate img
im_G = np.array((out+1)*127.5, dtype=np.uint8)
im_96 = np.array((imgs_96[0]+1)*127.5, dtype=np.uint8)
im_384 = np.array((imgs_384[0]+1)*127.5, dtype=np.uint8)
cv2.imwrite('./output/epoch_init_{}_G.jpg'.format(epoch), cv2.cvtColor(im_G, cv2.COLOR_RGB2BGR))
cv2.imwrite('./output/epoch_init_{}_96.jpg'.format(epoch), cv2.cvtColor(im_96, cv2.COLOR_RGB2BGR))
cv2.imwrite('./output/epoch_init_{}_384.jpg'.format(epoch), cv2.cvtColor(im_384, cv2.COLOR_RGB2BGR))
# train GAN (SRGAN)
for epoch in range(0, n_epoch + 1):
## update learning rate
epoch_time = time.time()
# real
sample_imgs_384 = random_crop(train_hr_imgs, 384)
sample_imgs_standardized_384 = standardized(sample_imgs_384)
# input
sample_imgs_96 = im_resize(sample_imgs_384,96,96)
sample_imgs_standardized_96 = standardized(sample_imgs_96)
# vgg19
sample_imgs_224 = im_resize(sample_imgs_384,224,224)
sample_imgs_standardized_224 = standardized(sample_imgs_224)
# loss
total_d_loss, total_g_loss, n_iter = 0, 0, 0
for i in tqdm.tqdm(range(step_num)):
step_time = time.time()
imgs_384 = sample_imgs_standardized_384[i * batch_size:(i + 1) * batch_size]
imgs_384 = np.array(imgs_384, dtype='float32')
imgs_96 = sample_imgs_standardized_96[i * batch_size:(i + 1) * batch_size]
imgs_96 = np.array(imgs_96, dtype='float32')
# vgg19 data
imgs_224 = sample_imgs_standardized_224[i * batch_size:(i + 1) * batch_size]
imgs_224 = np.array(imgs_224, dtype='float32')
## update D
errD = exe.run(SRGAN_d_program,
feed={'t_image': imgs_96, 't_target_image': imgs_384},
fetch_list=[d_loss])[0]
## update G
errG = exe.run(SRGAN_g_program,
feed={'t_image': imgs_96, 't_target_image': imgs_384, 'vgg19_input':imgs_224},
fetch_list=[g_loss])[0]
# print("Epoch [%2d/%2d] %4d time: %4.4fs, d_loss: %.8f g_loss: %.8f (mse: %.6f vgg: %.6f adv: %.6f)" %
# (epoch, n_epoch, n_iter, time.time() - step_time, errD, errG, errM, errV, errA))
total_d_loss += errD
total_g_loss += errG
n_iter += 1
log = "[*] Epoch: [%2d/%2d] time: %4.4fs, d_loss: %.8f g_loss: %.8f" % (epoch, n_epoch, time.time() - epoch_time, total_d_loss / n_iter, total_g_loss / n_iter)
print(log)
if (epoch != 0) and (epoch % 10 == 0):
out = exe.run(SRGAN_g_program,
feed={'t_image': imgs_96, 't_target_image': imgs_384, 'vgg19_input':imgs_224},
fetch_list=[test_im])[0][0]
# generate img
im_G = np.array((out + 1) * 127.5, dtype=np.uint8)
im_96 = np.array((imgs_96[0] + 1) * 127.5, dtype=np.uint8)
im_384 = np.array((imgs_384[0] + 1) * 127.5, dtype=np.uint8)
cv2.imwrite('./output/epoch_{}_G.jpg'.format(epoch), cv2.cvtColor(im_G, cv2.COLOR_RGB2BGR))
cv2.imwrite('./output/epoch_{}_96.jpg'.format(epoch), cv2.cvtColor(im_96, cv2.COLOR_RGB2BGR))
cv2.imwrite('./output/epoch_{}_384.jpg'.format(epoch), cv2.cvtColor(im_384, cv2.COLOR_RGB2BGR))
# save model
# d_models
save_pretrain_model_path_d = 'models/d_models/'
# delete old model files
shutil.rmtree(save_pretrain_model_path_d, ignore_errors=True)
# mkdir
os.makedirs(save_pretrain_model_path_d)
fluid.io.save_persistables(executor=exe, dirname=save_pretrain_model_path_d, main_program=SRGAN_g_program)
# g_models
save_pretrain_model_path_g = 'models/g_models/'
# delete old model files
shutil.rmtree(save_pretrain_model_path_g, ignore_errors=True)
# mkdir
os.makedirs(save_pretrain_model_path_g)
fluid.io.save_persistables(executor=exe, dirname=save_pretrain_model_path_g, main_program=SRGAN_g_program)
结果展示
import os
from PIL import Image
import matplotlib.pyplot as plt
img0 = Image.open('./output/epoch_1780_96.jpg')
img1 = Image.open('./output/epoch_1780_384.jpg')
img2 = Image.open('./output/epoch_1780_G.jpg')
plt.figure("Image Completion Result",dpi=384) # dpi = 384 显示的是原图大小
plt.subplot(2,3,1)
plt.imshow(img0)
plt.title('Low resolution',fontsize='xx-small',fontweight='heavy')
plt.axis('off')
plt.subplot(2,3,2)
plt.imshow(img1)
plt.title('Hing resolution',fontsize='xx-small',fontweight='heavy')
plt.axis('off')
plt.subplot(2,3,3)
plt.imshow(img2)
plt.title('Generate',fontsize='xx-small',fontweight='heavy')
plt.axis('off')
plt.show()

心得体会
在此篇文章之前,CNN网络在传统的单帧超分辨率重建上就取得了非常好的效果,但是当图像下采样倍数较高时,重建的得到的图片会过于平滑,丢失细节。此篇文章提出的利用GAN来进行超分辨率重建的方法,是第一个能恢复4倍下采样图像的框架。SRGAN这个网络的最大贡献就是使用了生成对抗网络(Generative adversarial network)来训练SRResNet,使其产生的HR图像看起来更加自然,有更好的视觉效果,更接近自然HR图像。
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250






