资源下载
资源下载

【Demo】基于语料库与NLP方法的中文幽默计算与检测项目

文件列表(压缩包大小 63.33M)
免费
概述
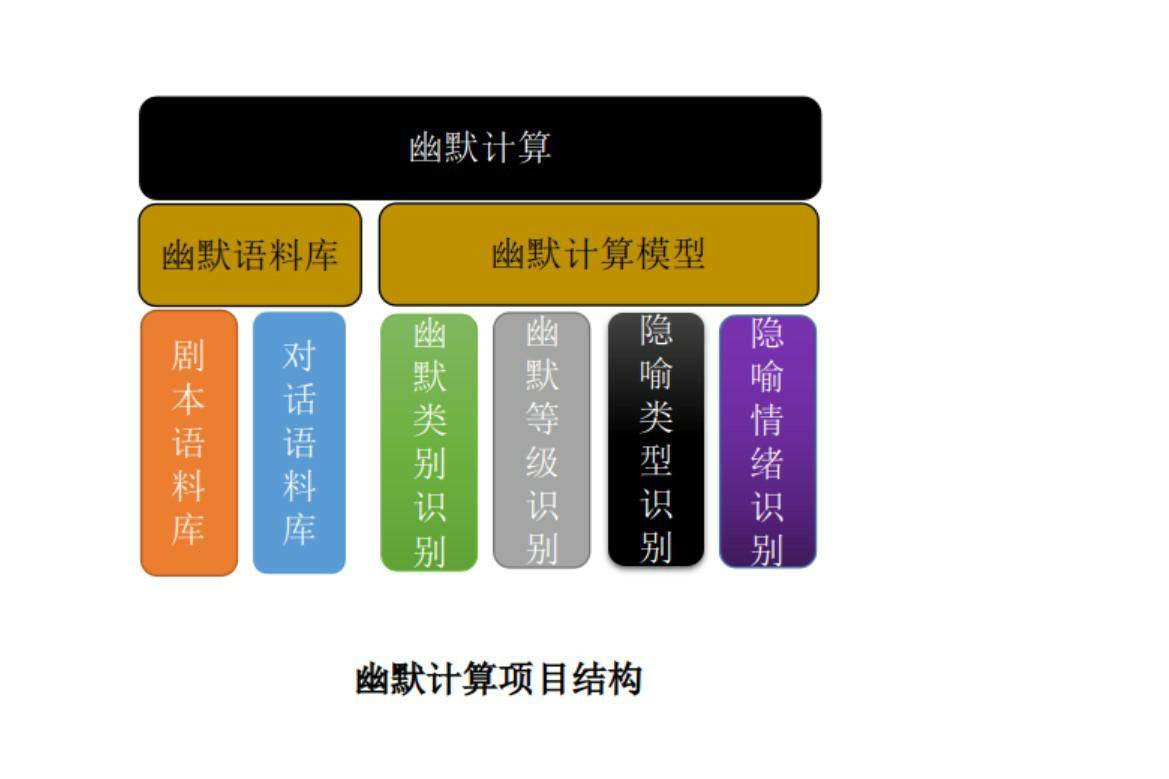
项目介绍
幽默多指令人发笑的品质或者具有发笑的能力,它是一种特殊的语言表达方式,是生活中活跃气氛、化解尴尬的重要元素。近年来随着人工智能的快速发展,如何利用计算机技术识别和生成幽默逐渐称为自然语言处理领域研究热点之一,即幽默计算。幽默计算旨在赋予计算机识别、生成幽默的能力,它涉及信息科学、认知语言学、心理学等多个学科的交叉,在人类语言的理解乃至世界文化的交流方面,都具有重要的理论和应用价值。
幽默无处不在,计算机若能够理解各种幽默形式,将会极大程度地提高人机交互系统的性能。 本项目将从中文的幽默性出发,尝试完成以下两个目标:
1)建立起一个中文幽默文本语料库。 2)幽默计算模型的构建包括:
- 幽默等级识别模型
- 幽默类型识别模型
- 隐喻类型识别模型
- 隐喻情绪识别模型
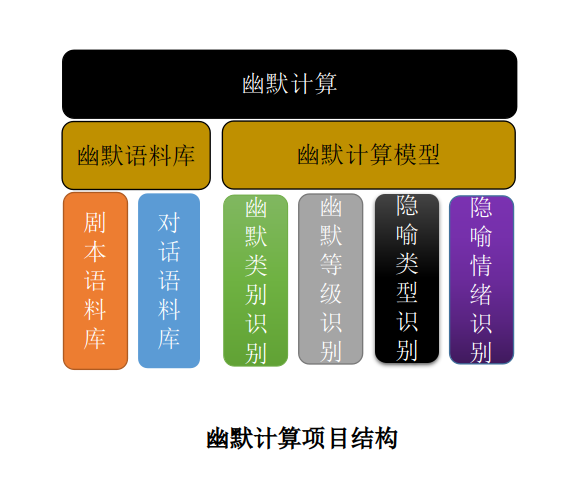
中文幽默文本语料库的构建
程序主目录:BuildCorpus 语料收集:BuildCorpus/corpus_spider.py 语料整理:BuildCorpus/collect_news.py 相声小品语料:对话集,BuildCorpus/dialog
语料简介
数量:6032个剧本、也称话题集, 352834条对话 对话举例:
'''
应聘男:各位同事大家好!
应聘女甲:欢迎大家来指导!
应聘女乙:不管节目好不好!
傻子:我用力过猛了,就变成这样了!
应聘男:你拉裤子了?
傻子:不是!、、、我使用我的洪荒之力,扶了一个跌倒的大妈!结果,就只剩下一条裤衩了!
应聘男:哦!难怪呢!土豪啊!敢吃青岛大虾,敢扶大爷大妈!有钱就是任性啊!这逼装的我给满风!(2016网络火爆热词)
应聘男:这你就不懂了吧?把傻子叫来,不是显得咱聪明了吗?咱不是有垫背的了吗?
应聘女:哎!对呀!、、、还是你聪明!
应聘男:那还用说!、、、、、、傻子,来!一会见了人家考官啊!一定要叫“女神”
傻子:这次你们不骗我?
应聘女乙:哎呀!这次不骗你!走啦,应聘去!
傻子:好的!
考官:哦!进来坐下吧!
考官:就你这样子,还龙的传人啊?
傻子:我是、、、恐龙的传人。
傻子:哦!你们X经理说了“女人里面的神经病,就叫女神”
考官:你、、、你这人是不是傻啊?
傻子:我才不傻呢!要说傻,孙悟空才是千古第一傻人!
傻子:他在蟠桃园里把七仙女定住,他妈的,那傻叉竟然去吃桃了!傻的都不可原谅了!这要是我、、、、、(欲言又止)
考官:这要是你!你会怎样啊?
傻子:这要是我,我一定偷他一颗桃树种回家,以后就不用买桃了!
'''
中文幽默计算模型
模型思想:采用四层双向lstm进行网络搭建,给出一个初步的baseline.以下是训练实际情况.
| 模型 | 训练集 | 测试集 | 训练集准确率 | 测试集准确率 | 备注 | 模型名称 |
|---|---|---|---|---|---|---|
| 幽默等级 | 6436 | 1610 | 0.8891 | 0.6137 | 5分类 | BiLSTM |
| 幽默类型 | 5938 | 1460 | 0.9357 | 0.7096 | 3分类 | BiLSTM |
| 幽默类型 | 5938 | 1460 | 0.9357 | 0.7356 | 3分类 | CNN |
| 幽默类型 | 5938 | 1460 | 0.9357 | 0.7103 | 3分类 | CNN-ATT |
| 隐喻类别 | 3515 | 879 | 0.9166 | 0.8089 | 2分类 | BiLSTM |
| 隐喻情绪 | 2904 | 726 | 0.8134 | 0.5399 | 7分类 | BiLSTM |
总结
- 一直在想如何更多地从社会语言学的角度去进行自然语言处理的研究和探索工作,幽默计算可以是其中一个,本项目是对该想法的一个实现.
- 本项目完成了幽默语料库的构建工作,并使用基本的双向lstm模型,训练了四个模型,准确率还有很大优化空间
- 本项目后期将逐步加入Attention等机制,对现有模型基础进行更新,尝试是否可以进一步提高准确性
- 本项目的受到大连理工大学信息检索实验室工作的启发.
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250