 资源下载
资源下载
0
本质上讲,机器学习中有两种模型:生成模型和判别模型。
假设你有一个监督学习任务,其中是数据点的给定特征,而是相应的标签。
预测未来的𝑦的一种方法是从(,)学习一个函数𝑓,该函数学习𝑥并输出最可能的𝑦。由于正在学习如何区分不同类别的𝑥,因此此类模型属于判别模型。支持向量机,神经网络等方法都属于此类。即使能够非常准确地对数据进行分类,你也不知道数据是如何生成的。
第二种方法是对数据的生成方式进行建模,并学习一个函数𝑓(𝑥,𝑦),该函数对由𝑥和𝑦共同确定的配置给出得分。然后,可以通过找到分数最高的那一个𝑓(𝑥,𝑦)来为𝑥预测一个新𝑦。一个典型的例子是高斯混合模型。
假设你的数据如下所示:
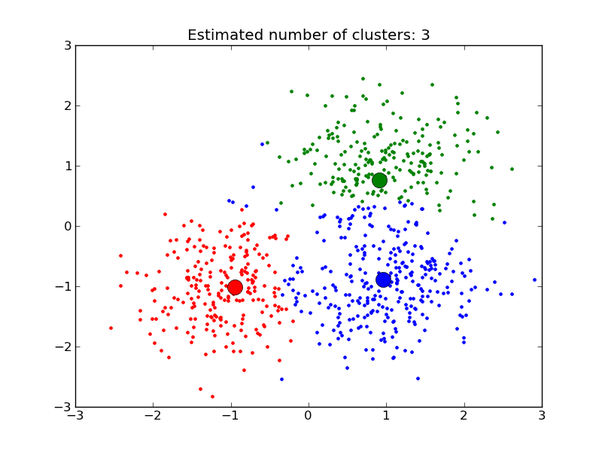 假定数据点的生成如下:
1.对一个簇进行采样:红色,绿色或蓝色。
2.给定簇,从该簇中心周围的高斯分布中绘制一个数据点。
第一步,需要一个分布𝑃(𝑦)。
第二步,需将分布𝑃(𝑥|),𝑃(𝑥|)和𝑃(𝑥|)定义为均值和方差不同的高斯分布。根据步骤1的输出,可以从其中一个分布中进行采样。
联合概率𝑃(𝑥,𝑦)由𝑃(𝑦)𝑃(𝑥|𝑦)给出。
因此,与判别模型设置不同,你已经明确地建模了数据的生成方式。请注意,真实数据几乎总是从复杂得多的过程中生成的,算法的性能将取决于模拟真实世界数据生成的能力。
假定数据点的生成如下:
1.对一个簇进行采样:红色,绿色或蓝色。
2.给定簇,从该簇中心周围的高斯分布中绘制一个数据点。
第一步,需要一个分布𝑃(𝑦)。
第二步,需将分布𝑃(𝑥|),𝑃(𝑥|)和𝑃(𝑥|)定义为均值和方差不同的高斯分布。根据步骤1的输出,可以从其中一个分布中进行采样。
联合概率𝑃(𝑥,𝑦)由𝑃(𝑦)𝑃(𝑥|𝑦)给出。
因此,与判别模型设置不同,你已经明确地建模了数据的生成方式。请注意,真实数据几乎总是从复杂得多的过程中生成的,算法的性能将取决于模拟真实世界数据生成的能力。
收藏







