资源下载
资源下载

我的观点是
LSTM有内存,而普通RNN没有。这意味着LSTM可以记住某些东西,而RNN则无法记住。
这个观点要么非常错误,要么就是基本上正确,取决于不同的观点。
首先我来解释一下为什么这是非常错误的。如果实际去实现RNN和LSTM,就可以意识到它们是通过及时地展开它们进行工作的,不需要考虑“内存”或“状态”,它只是标准的前馈网络。
 在此图中,存在U,V,W的转换,而对于不同类型的网络,这些转换可能存在也可能不存在。特别是对于经典的RNN,缺少的是哪些?答案是V。
在此图中,存在U,V,W的转换,而对于不同类型的网络,这些转换可能存在也可能不存在。特别是对于经典的RNN,缺少的是哪些?答案是V。
RNN计算输出并将相同的输出传递到下一个时间步,即st = ot。有人说经典RNN没有状态,但这明显是错误的,它们确实具有状态,并将这一状态传递给下一步的内容。在LSTM出现之前,通常认为状态和输出是同一件事,而更倾向于将此称为时间t的输出,而不是时间t的状态。
实际上,V部分位于网络本身之外,根本没有重复出现。这意味着使用传统的RNN时,如果提供正确的参数,就可以建立与LSTM基本上相同的模型(稍后再介绍)。
当LSTM出现时,它们从一种状态变为具有两种状态,一种可以称为“单元”,另一种可以称为“输出”。
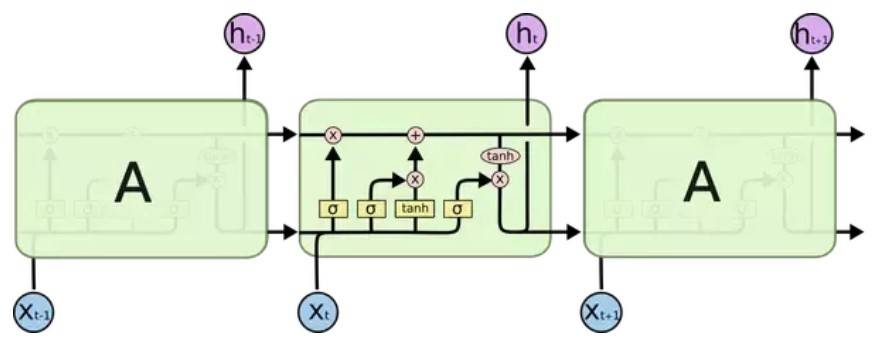
显然这里没有添加任何“内存”,它只是将两个信号而不是一个传递给了下一步,但是效果确很不错。如果查看第一行(单元格),会发现ct = ct-1(或ct中任何维数的子集)的情况很简单,可以将其视为随着时间的流逝而记住的东西。
但是,需要强调一下,即使在传统的RNN中,也可以进行设置,使“状态”(或其子集)随着时间的推移得以保留,就像LSTM一样。
如果认为拥有类似“记忆”的特殊东西很基础,那么下面展示一个GRU:
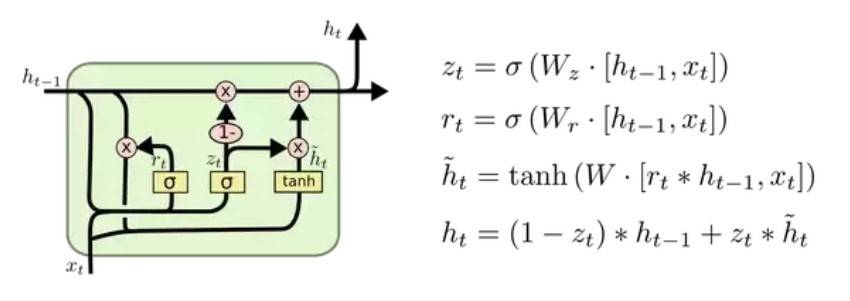
就像传统的RNN中一样,这里只有一个状态,但是转换非常复杂。它的输出就像RNN中的状态一样,没有什么多余的,但是与RNN不同,它很容易保存值,因此它的输出类似于内存。 GRU在很多情况下都是很有用的,通常可以像LSTM一样对类似内存的情况进行建模。
如果提供正确的权重,则RNN可以对类似记忆的现象进行建模。但是在经典RNN中,将值保留为状态的模型非常复杂,如梯度消失,激活函数的问题。但是通常为了对问题建模,需要类似内存的操作。如果使用LSTM或GRU,问题自然就解决了。
换句话说,如果希望循环网络有记忆,则应该使用LSTM和GRU,而不是传统的RNN。但是从理论上讲,后者同样有这个能力,不过前两者在经过某个步骤时能够轻松保存状态,而后者则比较麻烦。