资源下载
资源下载

0
Hypothesis函数
当预测的变量y只能采用离散值(即:分类)时,要使用逻辑回归。
考虑到二元分类问题(y只能取两个值),然后具有一组参数θ和一组输入特征x,可以定义Hypothesis函数,使其范围在[0,1]之间,其中g() 表示S型函数:
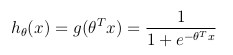
该Hypothesis函数同时表示在θ参数化的输入为x的条件下上y = 1的估计概率:
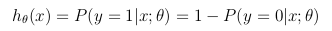
损失函数
损失函数代表了优化目标。
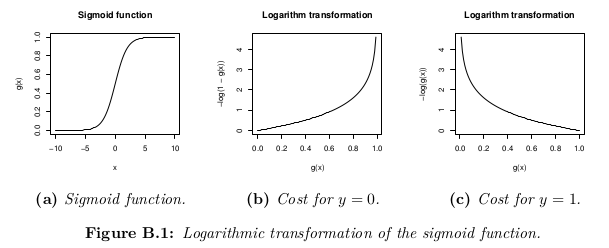
尽管损失函数的定义可以是hypothesis h_θ(x) 与训练集中所有m个样本中的实际值y之间的欧式距离的平均值,但前提是Hypothesis函数是由S型函数形成的 ,此定义将导致非凸损失函数,这意味着可以在达到全局最小值之前轻松找到局部最小值。 为了确保损失函数是凸的(因此确保收敛到全局最小值),要使用S形函数的对数来转换成本函数。
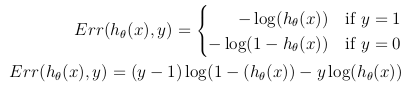
由此,可以将优化目标函数定义为训练集中损失/错误的平均值:
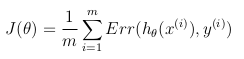
收藏