资源下载
资源下载
0
我将根据机器学习中常见问题的类型进行回答:
分类和回归问题:
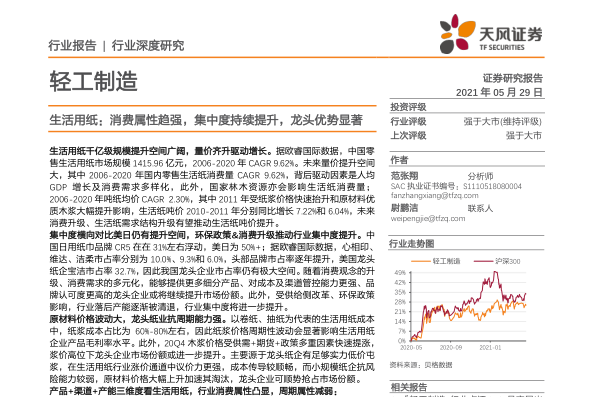
- XGBoost:通常能提供最佳的结果。
- 随机森林:它的性能往往比XGboost差一些,但由于易于部署并且在许多问题上都具有良好的效果,因此在业界得到了广泛的使用。
- SVM:它有许多有用的变体,对于某些问题来说是最好的选择,例如文本分类。
图片分类:
- 卷积神经网络:最近很热门的算法。
聚类:
- K-Means:很老的算法但目前还在行业中的大多数集群应用程序中使用,通常在精度和速度上没有其他算法好。
- HDBScan:一种“新”算法,非常适合检测不同大小和密度的簇。
推荐系统:
- 协同过滤:始终以某种方式成为系统的一部分。
- SVD ++:自Netflix竞赛以来,此方法已成为检测潜在功能的标准方法,并且始终是在推荐程序中提高结果的一种方法。请注意它与SVD无关。
降维:
- SVD: 永远是第一选择。 (PCA是一样的)
- NMF: 当SVD无法提供你需要的功能时。
表示:
- 深度自动编码器:几个深度学习系统的关键部分,也是找到表示数据集的最佳功能集的最佳方法之一。
- 稀疏过滤:一种计算量较少的好方法。
- Hash Kernels:速度非常快,通常会带来非常好的效果。
可视化:
- T-SNE:在二维或三维中可视化多维数据集的最新技术。
时间序列和顺序:
- LSTM:LSTM是递归神经网络,能够“记住”过去的事物,是情感分析等领域的最新技术。
除此之外,还有MCMC和贝叶斯网络:虽然很复杂,但理论上可以通过良好的贝叶斯分析和MCMC来解决任何问题。
收藏