资源下载
资源下载
1
我认为无法很精确地选择k,因为很难估计你的fold在多大程度上代表了你的整个数据集。我通常使用5倍交叉验证。这意味着20%的数据用于测试,并且它通常是相当准确的。
但是,如果你的数据集大小急剧增加,比如有超过100000个观察值,那么10倍的交叉验证将导致10000个实例。
此外,将数据分割成多少个fold可能由以下标准控制:确保每个fold具有相同比例的观测值以及给定的分类值(例如分类结果值)。这称为分层交叉验证。
下面的示例显示了为每个序列和测试集选择的特定观察值。索引直接用于原始数据数组以检索观测值。
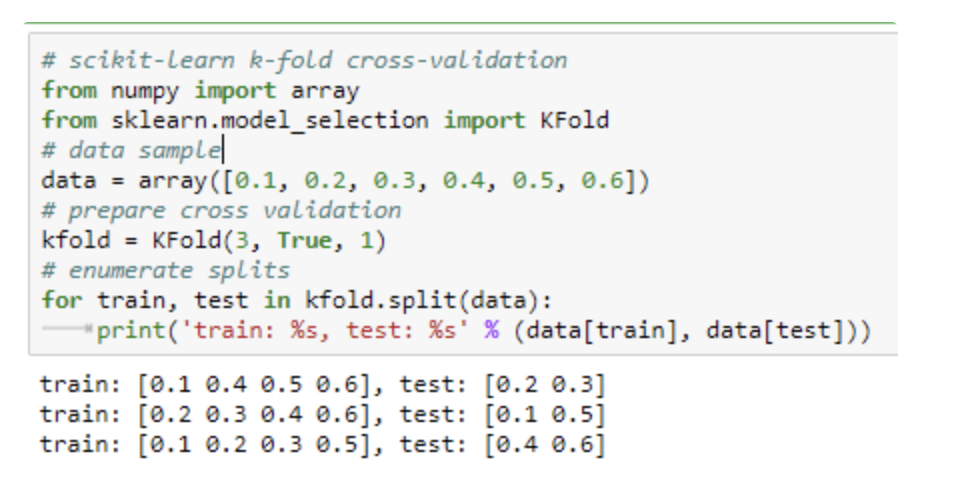 简言之,fold数取决于数据大小。我通常在较小的数据集上使用4或5倍,在较大的数据集上使用10倍。你要确保你的数据是无序的,这样fold就不会包含固有的偏差。
简言之,fold数取决于数据大小。我通常在较小的数据集上使用4或5倍,在较大的数据集上使用10倍。你要确保你的数据是无序的,这样fold就不会包含固有的偏差。
k的选择通常是5或10,但没有正式的规则。k越大,训练集和重采样子集之间的大小差异越小。当这种差异减小时,该技术的偏差就变小了。
另外,k-fold交叉验证不适用于评价不平衡分类器。
收藏