资源下载
资源下载

0
这里有很多很好的答案,其中许多是从不同的角度来看的。约瑟夫·雷辛格(Joseph Reisinger )最干净。我将根据我自己在数据驱动领域(算法交易)中的经验添加经验性答案。
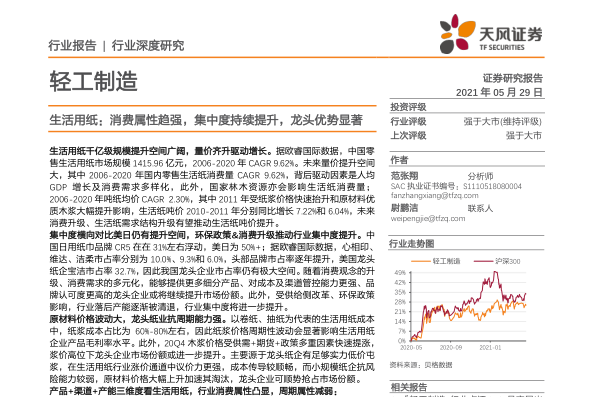
我们发现深度学习或深度神经网络方法是监督学习和无监督学习的良好组合,可改变每一层的成本函数。
在最初的层中,成本函数偏向于选择作为输入要素良好的要素,从而减少重建误差。在后面的层中,学习特征以便最大化预测准确性。
 我们之前采用的方法是将“无监督学习”步骤与“有监督学习”步骤分开。但是,这样做是在利用无监督学习。大多数变量使用诸如子集选择之类的方法来减少其参数空间。他们可能想要使用无监督的学习方法。
我们之前采用的方法是将“无监督学习”步骤与“有监督学习”步骤分开。但是,这样做是在利用无监督学习。大多数变量使用诸如子集选择之类的方法来减少其参数空间。他们可能想要使用无监督的学习方法。
但是,通常情况下,他们最终只是在使用监督学习的情况下这样做。在低信噪比的交易环境中,使用带有大量参数的监督学习容易过度拟合。
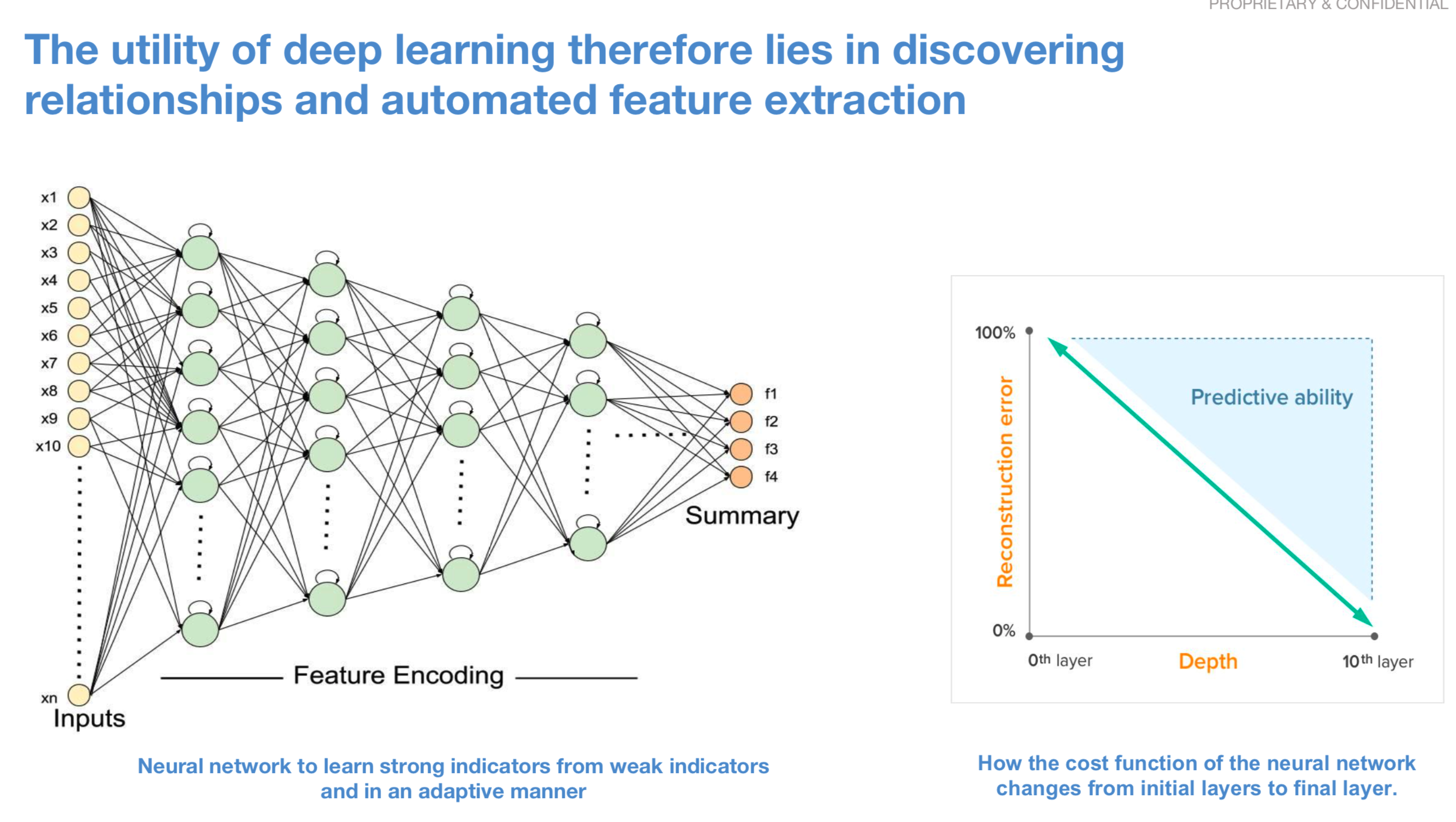
我们发现在计算预期收益和预期风险模型以得出资产分配alpha时很有用。这对我们来说不是新奇的。 每家试图推导alpha值的定量研究公司都在某种程度上试图计算出更好的预期收益和预期风险模型。
我们发现,DL方法用于计算预期收益和预期风险是将更多无监督学习引入组合的好方法。因此,我们已经能够减少参数空间中的自由度,从而改善了模型的样本拟合度。
收藏