资源下载
资源下载
0
基于物品的协同过滤算法的核心思想:给用户推荐那些和他们之前喜欢的物品相似的物品。
基于物品的协同过滤算法首先计算物品之间的相似度, 计算相似度的方法有以下几种:
基于共同喜欢物品的用户列表计算
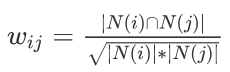
在此,分母中 N(i) 是购买物品 i 的用户数,N(j) 是购买物品 j 的用户数,而分子
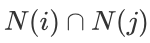 是同时购买物品i 和物品 j 的用户数。可见上述的公式的核心是计算同时购买这件商品的人数比例 。当同时购买这两个物品人数越多,他们的相似度也就越高。另外值得注意的是,在分母中我们用了物品总购买人数做惩罚,也就是说某个物品可能很热门,导致它经常会被和其他物品一起购买,所以除以它的总购买人数,来降低它和其他物品的相似分数。
是同时购买物品i 和物品 j 的用户数。可见上述的公式的核心是计算同时购买这件商品的人数比例 。当同时购买这两个物品人数越多,他们的相似度也就越高。另外值得注意的是,在分母中我们用了物品总购买人数做惩罚,也就是说某个物品可能很热门,导致它经常会被和其他物品一起购买,所以除以它的总购买人数,来降低它和其他物品的相似分数。基于余弦的相似度计算
上面的方法计算物品相似度是直接使同时购买这两个物品的人数。但是也有可能存在用户购买了但不喜欢的情况 所以如果数据集包含了具体的评分数据 我们可以进一步把用户评分引入到相似度计算中 。
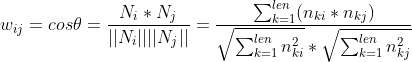
其中 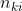 是用户 k 对物品 i 的评分,如果没有评分则为 0。
是用户 k 对物品 i 的评分,如果没有评分则为 0。
热门物品的惩罚
对于热门物品的问题,可以用如下公式解决:
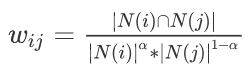
当
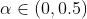 时,N(i) 越小,惩罚得越厉害,从而会使热门物品相关性分数下降。
时,N(i) 越小,惩罚得越厉害,从而会使热门物品相关性分数下降。
收藏