资源下载
资源下载
模型偏差
模型偏差-这是ML中“偏差”的经典解释,是指当模型不能很好的拟合数据的时候,与方差相反。
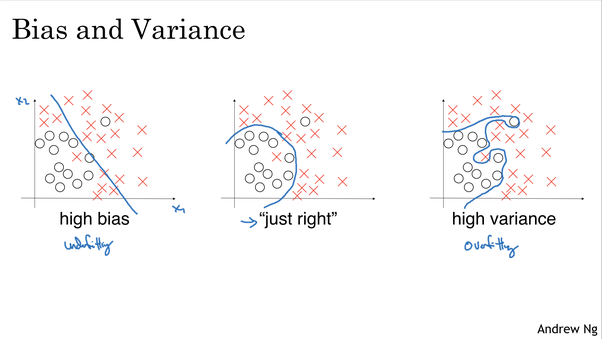 通过测量误差,当拟合不足时,与基本错误相比,训练集和测试集的错误率都很高(通常相似)。这与高方差情况相反-在这种情况下,可能会过度拟合训练数据。因此,训练数据将具有较低的错误率,但是测试集将具有较高的错误率。
通过测量误差,当拟合不足时,与基本错误相比,训练集和测试集的错误率都很高(通常相似)。这与高方差情况相反-在这种情况下,可能会过度拟合训练数据。因此,训练数据将具有较低的错误率,但是测试集将具有较高的错误率。
数据偏差
这是对偏差的一种较宽松的解释,当培训和测试数据集来自与测试/现实世界数据集不同的分布时,可能会发生这种情况。训练和测试集的错误率很低,而实际使用模型时,测试集或实际示例的错误率却很高。分析这种情况比较棘手,因为可能有不同的根本原因。一种直接方法是: 分析错误情况,并查看它们是否属于训练集中未表示的分布。 从训练和测试/真实世界中随机选择代表集,并分析分布。 执行上述操作的能力取决于使用的数据的类型和规模。例如,对图像进行处理可能很简单,而人类往往很容易解释这些图像(尽管即使在这种情况下,可能会有不同的参数)。但这可能需要用于其他和更复杂数据类型的更复杂的分析工具。
在训练数据中的性别、种族以及其他的小的偏见
为了防止我们的模型继承基础训练数据的偏见,有很多研究和工作致力于解决此问题。这里有一篇关于处理性别和词嵌入中其他偏见的出色论文(https://arxiv.org/pdf/1607.06520.pdf%20(https%3A//arxiv.org/pdf/1607.06520.pdf)) 基于自然语言处理的机器学习根据单词在大型文本语料库(互联网,新闻站点,维基百科等)中的作用为单词赋予“含义”。不幸的是,这些含义似乎继承并放大了原始文本中出现的偏见和成见。这些偏见会影响使用这些模型的许多应用,例如:大学入学,简历筛选,学分认可等。此文涵盖了相当多的主题,但从根本上讲,它提供了一种数学上的识别和测量偏见的方法,然后提出去偏算法。 转载自:https://www.quora.com/By-what-criteria-can-humans-label-machine-learning-results-as-biased