资源下载
资源下载

给数据输入增加噪声
在这种情况下,“随机数据输入”可能意味着:让我们将数据某些特征随机设置为0(有时甚至多达一半),以生成新的“损坏”数据集。我们将从输入的随机数据中学习,在这种情况下输出是不确定的。
这是一个数字数据集:
 原始图像在左侧,损坏的图像在中间。此机器学习任务的目标是从中间的损坏图像中重建原始图像。有了足够的培训数据,就有可能做到;重建的图像是右边的图像。它们看起来与左侧的相似!
使用的推广的去噪自动编码器(神经网络)是能够完成此任务的。令人惊讶的是,当图像中多达一半的像素被破坏时,去噪自动编码器也可以恢复原始图像。
这是去噪自动编码器学习的功能,没有任何数据损坏
原始图像在左侧,损坏的图像在中间。此机器学习任务的目标是从中间的损坏图像中重建原始图像。有了足够的培训数据,就有可能做到;重建的图像是右边的图像。它们看起来与左侧的相似!
使用的推广的去噪自动编码器(神经网络)是能够完成此任务的。令人惊讶的是,当图像中多达一半的像素被破坏时,去噪自动编码器也可以恢复原始图像。
这是去噪自动编码器学习的功能,没有任何数据损坏
 随着数据损坏:
随着数据损坏:
 随着数据损坏这些特征变得更加清晰,其中许多与笔触相对应!
一个相关的概念是dropout -深度学习中一种非常有用的技术,可以防止过度拟合,该函数通过在学习过程中随机破坏神经网络的内部来进行操作。
随着数据损坏这些特征变得更加清晰,其中许多与笔触相对应!
一个相关的概念是dropout -深度学习中一种非常有用的技术,可以防止过度拟合,该函数通过在学习过程中随机破坏神经网络的内部来进行操作。
随机图像的结构
很难说“随机图像”到底是什么。我们必须更具体地讨论某个随机图像,这是ImageNet数据集:
 这些图片肯定不是随机的,因为这些图片不是从Internet上随机绘制的。但是,所涉及的类别是随机的,因为它们是任意的,尽管拍摄的某些照片相对晦涩难懂。例如:波斯猫,狒狒,间歇泉,欧洲鸡胆,滤油器,比萨饼和电钻。
基于ImageNet数据集,训练得到一个深层神经网络后,我们可以将每个图像表示为散点图中的一个点,以检查所涉及的结构。结果表明,可以存在相当多的结构,
这些图片肯定不是随机的,因为这些图片不是从Internet上随机绘制的。但是,所涉及的类别是随机的,因为它们是任意的,尽管拍摄的某些照片相对晦涩难懂。例如:波斯猫,狒狒,间歇泉,欧洲鸡胆,滤油器,比萨饼和电钻。
基于ImageNet数据集,训练得到一个深层神经网络后,我们可以将每个图像表示为散点图中的一个点,以检查所涉及的结构。结果表明,可以存在相当多的结构,
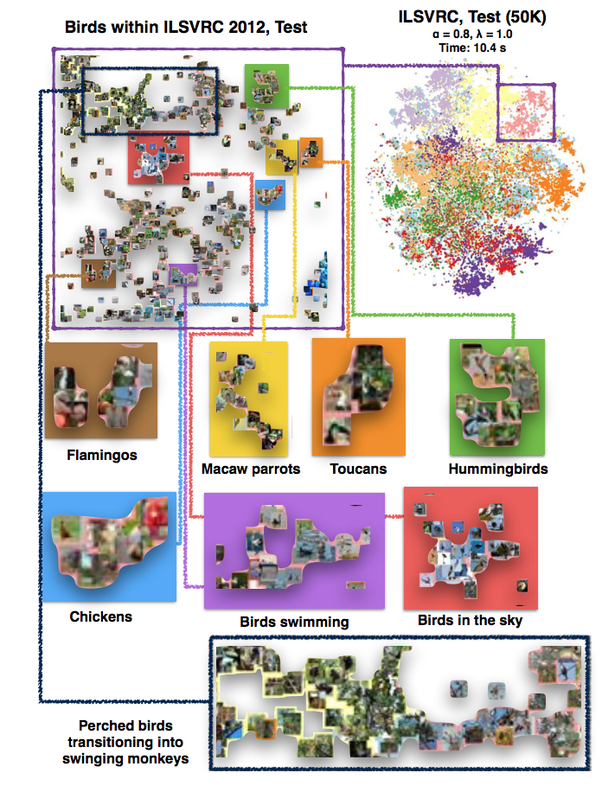 当然,放入此t-SNE变体(alpha-beta SNE)的图像可能是“随机的”,因为它们是任意的,但在训练的过程中肯定有很多结构。机器学习可以发现这种结构。
当然,放入此t-SNE变体(alpha-beta SNE)的图像可能是“随机的”,因为它们是任意的,但在训练的过程中肯定有很多结构。机器学习可以发现这种结构。
生成对抗网络
到目前为止,涉及的讨论已经绕过了问题原本的含义,将随机噪声传递到了机器学习算法中。在这种情况下,很难不谈论生成对抗网络(GAN)。从本质上讲,GAN尝试通过训练两个组件来捕获数据集的概率分布:(1)生成器和(2)鉴别器。
随着不断地训练,生成器变得越来越好,它能够生成很真实的数据,以至于无法与训练数据区分开。
那么如何生成数据呢?我们将“随机数据输入”传递到神经网络。
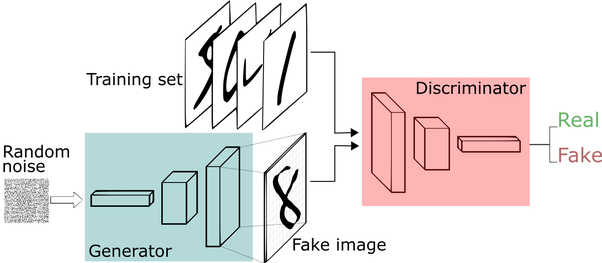 GAN已在多个领域进行了实践。他们甚至可以创造艺术!
GAN已在多个领域进行了实践。他们甚至可以创造艺术!
 有了GAN,随机的垃圾数据进入了神经网络,但是能够输出很有艺术感的结果-这不是很吸引人吗?
有了GAN,随机的垃圾数据进入了神经网络,但是能够输出很有艺术感的结果-这不是很吸引人吗?
转载自:https://www.quora.com/What-happens-if-we-mix-machine-learning-with-random-data-input