 资源下载
资源下载




【毕业设计】基于tensorflow、keras/pytorch实现对自然场景的文字检测及端到端的OCR中文文字识别

文件列表(压缩包大小 62.71M)
免费
概述
基于tensorflow、keras/pytorch实现对自然场景的文字检测及端到端的OCR中文文字识别
功能
- 文字检测 实现keras端到端的文本检测及识别(项目里面有两个模型keras和pytorch。)
- 不定长OCR识别
Ubuntu下环境构建
Bash
##GPU环境
sh setup-python3-gpu.sh
##CPU python3环境
sh setup-python3-cpu.sh
##额外依赖的安装包
apt install graphviz
pip3 install graphviz
pip3 install pydot
pip3 install torch torchvision
模型
一共分为3个网络
- 文本方向检测网络-Classify(vgg16)
- 文本区域检测网络-CTPN(CNN+RNN)
- EndToEnd文本识别网络-CRNN(CNN+GRU/LSTM+CTC)
文字方向检测-vgg分类
基于图像分类,在VGG16模型的基础上,训练0、90、180、270度检测的分类模型. 详细代码参考angle/predict.py文件,训练图片8000张,准确率88.23% 模型地址[BaiduCloud](链接:https://pan.baidu.com/s/1Sqbnoeh1lCMmtp64XBaK9w 提取码:n2v4)
文字区域检测CTPN
支持CPU、GPU环境,一键部署, 文本检测训练参考
OCR 端到端识别:CRNN
ocr识别采用GRU+CTC端到到识别技术,实现不分隔识别不定长文字
提供keras 与pytorch版本的训练代码,在理解keras的基础上,可以切换到pytorch版本,此版本更稳定
使用
体验
运行demo.py或者pytorch_demo.py(建议) 写入测试图片的路径即可,如果想要显示ctpn的结果,修改文件./ctpn/ctpn/other.py 的draw_boxes函数的最后部分,cv2.inwrite('dest_path',img),如此,可以得到ctpn检测的文字区域框以及图像的ocr识别结果
- 在进行体验的时候,注意要更改里面的一些内容(比如模型文件等)
模型训练
1 对ctpn进行训练
定位到路径
--./ctpn/ctpn/train_net.py预训练的vgg网络路径[VGG_imagenet.npy](链接:https://pan.baidu.com/s/1jzrcCr0tX6xAiVoolVRyew 提取码:a5ze ) 将预训练权重下载下来,pretrained_model指向该路径即可, 此外整个模型的预训练权重[checkpoint](链接:https://pan.baidu.com/s/1oS6_kqHgmcunkooTAXE8GA 提取码:xmjv )
ctpn数据集还是百度云 数据集下载完成并解压后,将
.ctpn/lib/datasets/pascal_voc.py文件中的pascal_voc类中的参数self.devkit_path指向数据集的路径即可
2 对crnn进行训练
keras版本
./train/keras_train/train_batch.py model_path--指向预训练权重位置MODEL_PATH---指向模型训练保存的位置 [keras模型预训练权重](链接:https://pan.baidu.com/s/14cTCedz1ESnj0mM9ISm__w 提取码:1kb9)pythorch版本
./train/pytorch-train/crnn_main.pyparser.add_argument( '--crnn', help="path to crnn (to continue training)", default=预训练权重的路径,看你下载的预训练权重在哪啦) parser.add_argument( '--experiment', help='Where to store samples and models', default=模型训练的权重保存位置,这个自己指定)[pytorch预训练权重](链接:https://pan.baidu.com/s/1kAXKudJLqJbEKfGcJUMVtw 提取码:9six)
文字检测及OCR识别结果

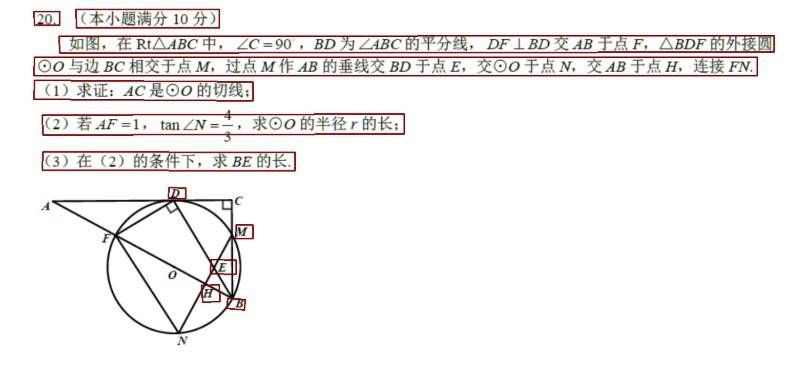
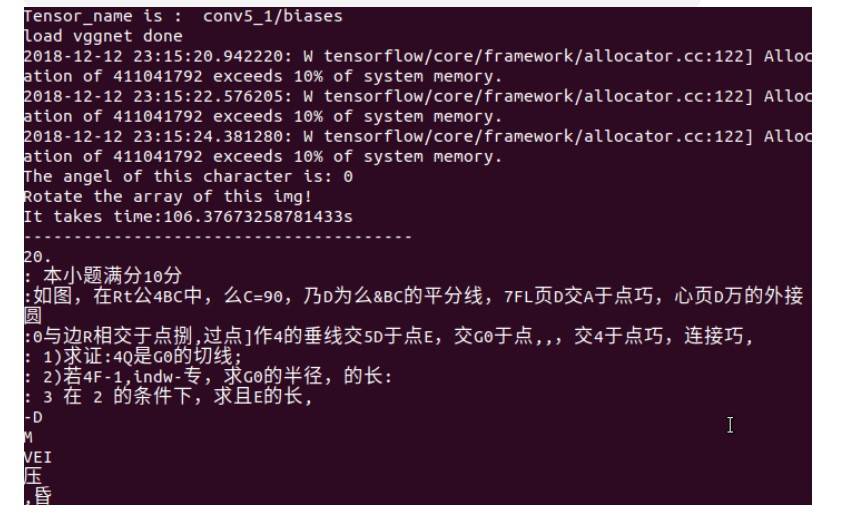
主要是因为训练的时候,只包含中文和英文字母,因此很多公式结构是识别不出来的
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







