 资源下载
资源下载




推荐系统论文归类总结

文件列表(压缩包大小 1.60M)
免费
概述
推荐系统论文归类总结 本文主要记录较新的推荐系统论文,并对类似的论文进行总结和整合。
目录
- 推荐系统论文归类总结
- 综述
- 协同过滤理论
- 矩阵分解
- 因子分解机
- 基于内容的推荐
- 基于DNN的推荐
- 基于标签的推荐
- 基于自编码器
- Item2Vec
- 上下文感知模型
- 基于视觉的推荐
- 基于RNN的推荐
- 基于图的推荐
- 基于树的推荐
- 公司的推荐系统的发展历程
- 数据集
- 参考资料
- 版权声明
综述
- 《Deep Learning based Recommender System: A Survey and New Perspectives》
- 《Use of Deep Learning in Modern Recommendation System: A Summary of Recent Works》 这几个综述比较全面,介绍了目前的深度学习在推荐系统中的应用。
协同过滤理论
1.《Application of Dimensionality Reduction in Recommender System - A Case Study》推荐系统的维度下降技术。
这是发表于2000年的“古老”论文,该文是最早探讨如何解决协同过滤数据量很大时的问题。这个论文提出了使用传统的SVD降维的技术。
这个文章提出推荐系统可以分为两部分:预测、推荐。预测可以使用加权和,推荐使用TopN。可能因为这个文章特别早吧,他认为推荐系统面临的主要问题是三个:稀疏,规模,“同义词”。当数据集稀疏的时候,皮尔逊近邻算法可能根本无法使用。规模很好理解。这个同义词的意思是两个相似的物品名字不同,推荐系统不能发现他们之间的隐相关性。同义词问题没看到这个文章怎么解决的,事实上我也没看到其他论文上如何解决这个问题,甚至已经不认为这是推荐系统要解决的问题了。
该文认为SVD的任务有两个: 1.捕捉用户和商品的隐层关系,允许我们计算用户对商品打分的预测值。 2.对原始的用户和商品关系进行降维,并且在低维空间计算邻居。
该传统的SVD是一种矩阵分解方法,这种方法的缺点是需要先把评分矩阵缺值补足,是一种线性代数里的求解析解的方法。这种方法可以研究的一个点就是如何进行缺失值填补,不同的填充方法,对结果产生不同的影响。另外就是SVD降维是代表维度k值的选取,这个需要使用实验获得。另外,真正的预测是放在线下运行的,可以在用户的访问时迅速做出推荐。
总体而言,这个文章介绍了SVD如何在推荐系统中使用,并通过实验说明了如何做预测和推荐。因为该矩阵分解方法和后来的矩阵分解差异已经很大,所以不放入后面的矩阵分解篇幅中。
2.《Amazon.com Recommendations Item-to-Item Collaborative Filtering》亚马逊发表的基于物品的协同过滤
在 User-based 方法中,随着用户数量的不断增多,在大数量级的用户范围内进行“最近邻搜索”会成为整个算法的瓶颈。Item-based 方法通过计算项之间的相似性来代替用户之间的相似性。对于项来讲,它们之间的相似性要稳定很多,因此可以离线完成工作量最大的相似性计算步骤,从而大大降低了在线计算量,提高推荐效率。
在 Item-based 方法中,要对 A 和 B 进行项相似性计算,通常分为两步:1)找出同时对 A 和 B 打过分的组合;2)对这些组合进行相似度计算,常用的算法包括:皮尔森相关系数、余弦相似性、调整余弦相似性和条件概率等。伪代码如下:

3.《Item-Based Collaborative Filtering Recommendation Algorithms》影响最广的,被引用的次数也最多的一篇推荐系统论文。
文章很长,非常详细地探讨了基于Item-based 方法的协同过滤,作为开山之作,大体内容都是很基础的知识。文章把Item-based算法分为两步:
(1)相似度计算,得到各item之间的相似度
- 基于余弦(Cosine-based)的相似度计算
- 基于关联(Correlation-based)的相似度计算
- 调整的余弦(Adjusted Cosine)相似度计算
(2)预测值计算,对用户未打分的物品进行预测
- 加权求和。用户u已打分的物品的分数进行加权求和,权值为各个物品与物品i的相似度,然后对所有物品相似度的和求平均,计算得到用户u对物品i打分。
- 回归。如果两个用户都喜欢一样的物品,因为打分习惯不同,他们的欧式距离可能比较远,但他们应该有较高的相似度 。在通过用线性回归的方式重新估算一个新的R(u,N)。
文章很经典,没有太难理解的部分,可以看别人的笔记:https://blog.csdn.net/huagong_adu/article/details/7362908
矩阵分解
1.《Matrix Factorization Techniques for Recommender Systems》矩阵分解,推荐系统领域里非常经典、频繁被引用的论文。
这个论文是推荐系统领域第一篇比较正式、全面介绍融合了机器学习技术的矩阵分解算法(区别于传统的SVD矩阵分解)。矩阵分解是构建隐语义模型的主要方法,即通过把整理、提取好的“用户—物品”评分矩阵进行分解,来得到一个用户隐向量矩阵和一个物品隐向量矩阵。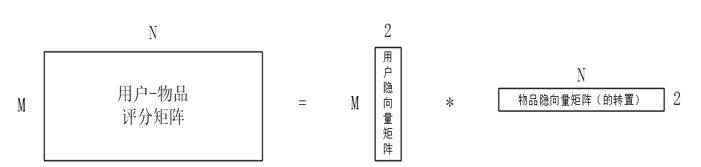
在得到用户隐向量和物品隐向量(如都是2维向量)之后,我们可以将每个用户、物品对应的二维隐向量看作是一个坐标,将其画在坐标轴上。虽然我们得到的是不可解释的隐向量,但是可以为其赋予一定的意义来帮助我们理解这个分解结果。比如我们把用户、物品的2维的隐向量赋予严肃文学(Serious)vs.消遣文学(Escapist)、针对男性(Geared towards males)vs.针对女性(Geared towards females),那么可以形成论文中那样的可视化图片:
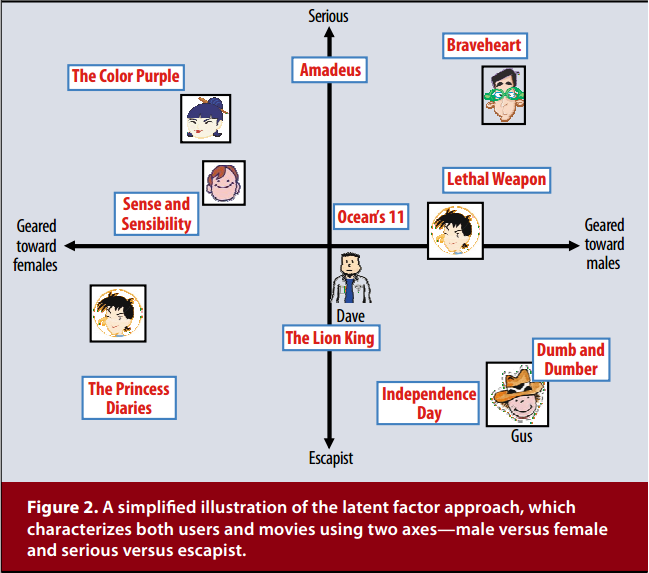
这种矩阵分解方法区别于传统的SVD,这种方法不仅不需要进行缺失值填补,而且相比于线性代数里的奇异值分解,该方法从问题的描述上就是一个最优化问题。给出目标损失函数,然后优化它。所以已经和SVD没什么关系了。
矩阵分解算法具有的融合多种信息的特点也让算法设计者可以从隐式反馈、社交网络、评论文本、时间因素等多方面来弥补显示反馈信息不足造成的缺陷,可以根据需要很容易的把公式进行改变。比如考虑到时间变化的用户、项目的偏差,可以对预测评分函数改写成:

2.《Feature-Based Matrix Factorization》从公式推导到优化方法,到参数更新策略讲得非常详细的一篇工程实践论文。
非常好的一篇文章,把矩阵分解讲的特别详细,强烈推荐一看。提出了基于特征的矩阵分解模型。其实这个模型并不是一个新的大的改变,只不过是对于已有的很多矩阵分解的变体进行了一个统一的形式定义。该文章把矩阵分解分为了用户特征、物品特征、全局特征,对这三个特征都有相应的系数矩阵。这个模型很容易地可以加上Pairwise方法,时间系数,邻域信息,层次信息等。本文也给出了优化矩阵分解模型选用的方法,参数更新公式,计算加速的方法等非常详细的说明。总体的框架如下图。
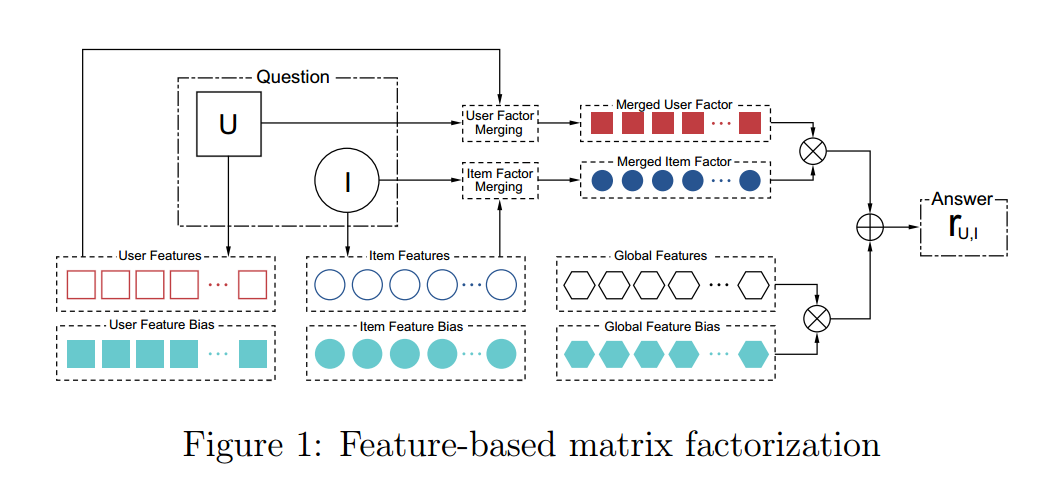
这个矩阵分解的速度可以很快,有点类似FM,不过比FM多了全局偏置。值得一看,一定会对矩阵分解有更深的认识。这个文章是偏向于工程实践的,所以循序渐进地引出来每个式子。和普通的论文的佶屈聱牙相比,绝对能看懂。唯一可惜的是没有看到公开的代码,如果发现了再补到这里。
3.《Probabilistic Matrix Factorization》PMF是对于基本的FunkSVD的概率解释版本,殊途同归
本文要提出一个解决非常系数和不平衡的数据集的模型,解决了很多在NetFlix数据集上运用矩阵分解失败的两个原因: 1.没法适用于大规模数据集 2.对于冷门的用户很难做推荐
它假设评分矩阵中的元素Rij是由用户潜在偏好向量Ui和物品潜在属性向量Vj的内积决定的,并且服从以下的正态分布:
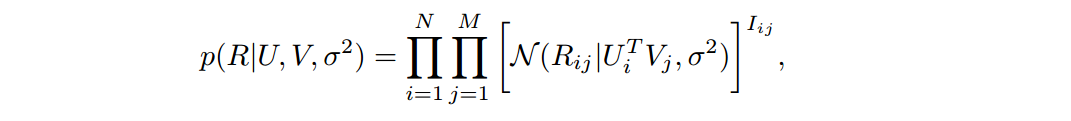
同时,假设用户偏好向量与物品偏好向量服从于均值为0以下的正态分布:
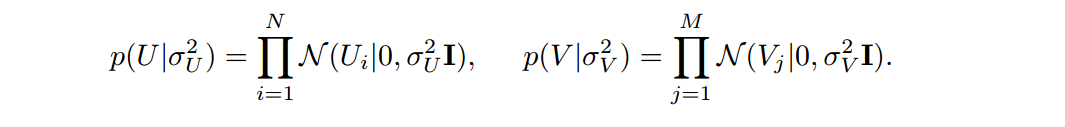
对正太分布取log,之后会发现后面的正则化项和超参与数据集分布有关,是不变的。所以可以得到了要优化的目标方程:
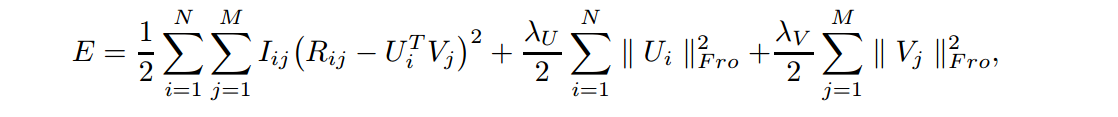
所以,绕了一圈之后会发现,如果假如评分、用户、物品的向量是正太分布的话,那么就能通过数学方法推导出和SVD基本一致的目标方程,所以标题才直接取名概率矩阵分解机。这个思路很清奇,文章的后面又基于这个基本的目标方程进行了两种改进。
4.《Regression-based Latent Factor Models》基于回归的隐因子模型
这个论文其实就是对《Probabilistic Matrix Factorization》进行了改进。
本文也是基于高斯先验,但是把正太分布的均值从0-均值改成了基于特征的回归方法来计算,使得模型假设更有说服力。
优点是三个: 1.一个模型同时解决了冷热启动问题; 2.减少了使用共现物品或用户的相关性; 3.给预测提供了附加信息,提高了准确度。
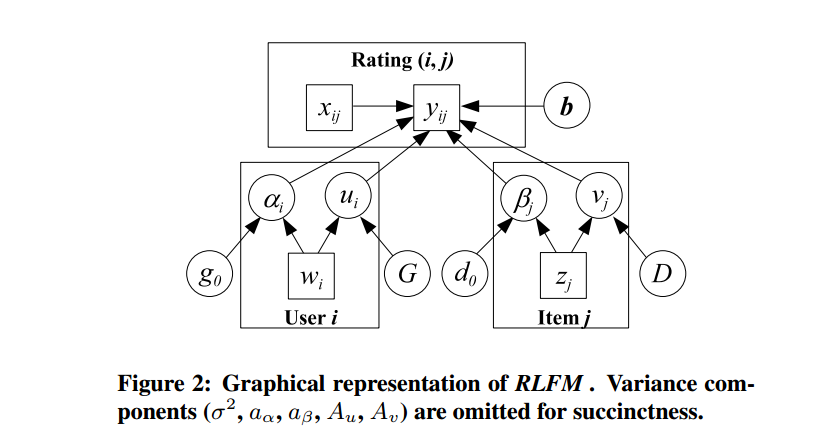
5.《Collaborative Filtering with Temporal Dynamics》加入了时间变量的协同过滤
这个论文的想法是显然易见的:用户给物品的打分是随着时间变化而变化的。因此,该文在以前模型的基础上加入了时间因素。文中对两种推荐方法:基于邻域的模型、隐因子模型都做了相应的改进。主要的公式是:
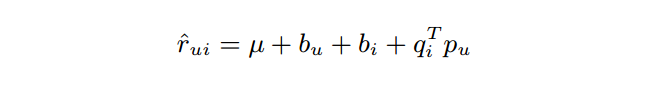
实际应用的模型是基于SVD++改进的。本文基于这样的思想:用户和物品的偏置都会随着时间变化,用户的隐因子也会改变,但是物品的隐因子认为是不变的。另外在思考这个问题的时候也要考虑到把时间分箱时要兼顾到粗细粒度,本文还综合考虑了用户喜好随着时间的渐变和突变。因为这个文章比较全面系统,我觉得可以多看几遍。
6.《Factorization Meets the Neighborhood: a Multifaceted Collaborative Filtering Model》近邻方法+因子分解
这个文章自称是第一篇把近邻方法和因子分解方法融合到一起的论文。难点其实在于把近邻方法转换为因子分解方法相似的通过迭代更新参数进行求解的方式,而传统的近邻方法是基于原始数据集统计求解的、不需要迭代。
文章对最近邻模型只做出了多个改进:模型参数通过训练得到,加入了隐式数据,用户偏置项使用学习得到,对邻域个数进行了归一化。对因子分解方法主要采用了SVD++方法。最后的融合模型如下图,使用梯度下降更新参数。这个模型相当于三层模型的累加:基准模型+因子分解模型+最近邻模型。
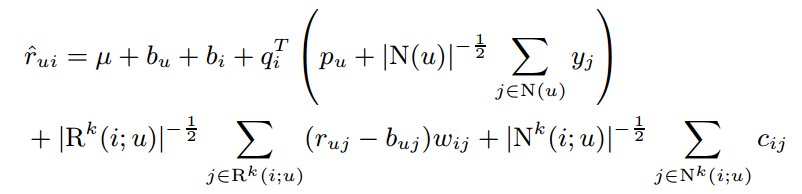
这篇解读相当不错:https://blog.csdn.net/fangqingan_java/article/details/50762296
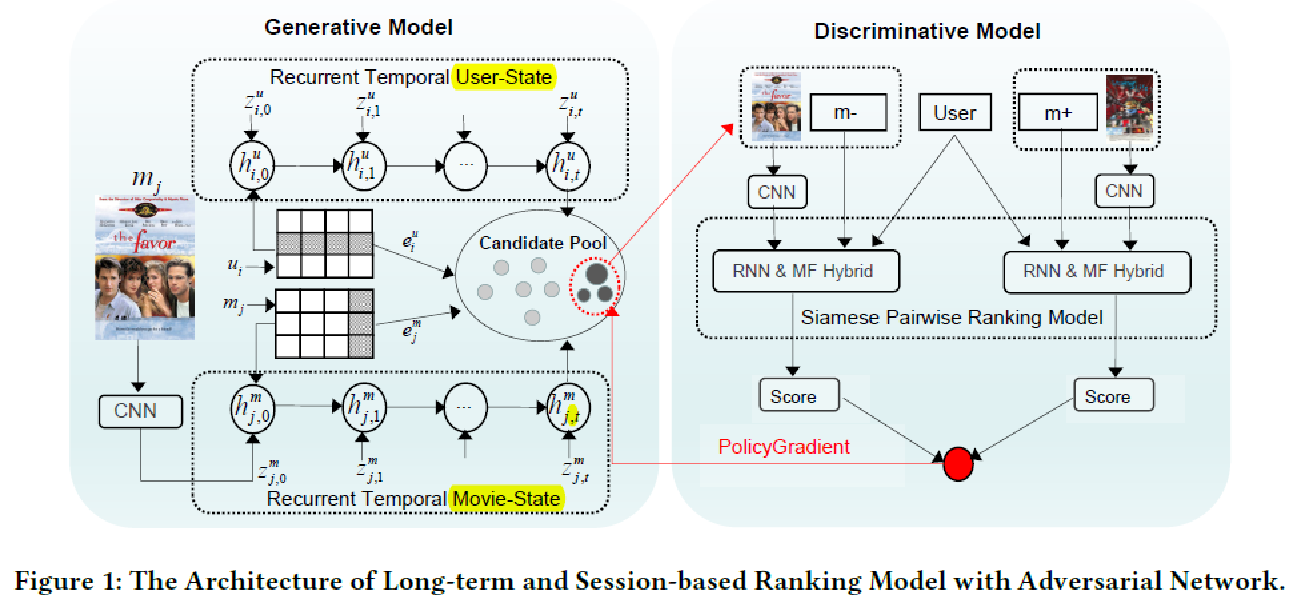
7.《Leveraging Long and Short-term Information in Content-aware Movie Recommendation》几个模型的融合
这个文章简直好大全。MF,LSTM,CNN,GAN全都用上了。
本质是学习得到用户和电影的隐层向量表示。学习的方式是最小化能观测到的电影评分预测值和真实评分值的方根误差。即MF的公式是:
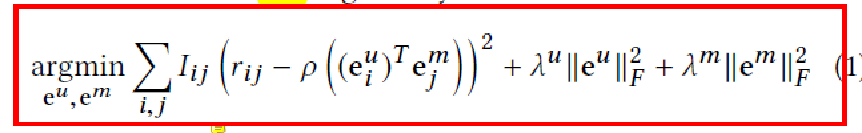
另外,矩阵分解不能学到关于时间变化的用户口味的变化,所以本文用到了LSTM。文章整体的架构如下。
因子分解机
1.《Factorization Machines》大名鼎鼎的FM
FM模型是一个可以用于大规模稀疏数据场景下的因式分解模型,这个模型的求解是线性时间复杂度的,他可以使用原始数据直接求解而不需要像SVM一样依赖支持向量。另外FM是个通用的模型,可以在任何实数数据上使用,可以做分类和回归甚至能做排序等任务。
FM的思想是在线性回归的基础上,增加了两个特征的线性组合,求解线性组合的方式是使用了矩阵分解的方式。因为如果数据本身就很稀疏,于是两个变量的共现数据极少,但是矩阵分解使得不同的特征对不再是完全独立的,而它们的关联性可以用隐式因子表示,这将使得有更多的数据可以用于模型参数的学习。目标函数如下:
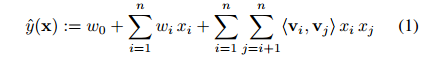
上面的二次项矩阵可以通过数学进行优化,使得时间复杂度降为O(kN)。
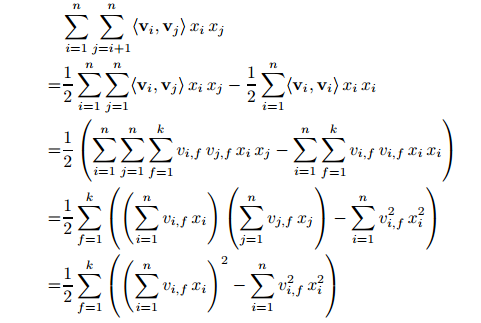
2.《Field-aware Factorization Machines for CTR Prediction》大名鼎鼎的FFM
FFM是对FM的改进,添加了Field的概念,也就是说每个特征归于哪一类。假设Field有f个。那么每个特征都要有f个隐向量。当两个特征做交叉的时候,使用每个特征与另外一个Field对应的向量求点积。这样的话,就能保证相同Field对同一个特征的作用是相同的,而不同Field的特征对同一个特征的作用是不同的。
另外,FFM不能向FM那样使用数学优化了,所以时间复杂度是O(kN^2).

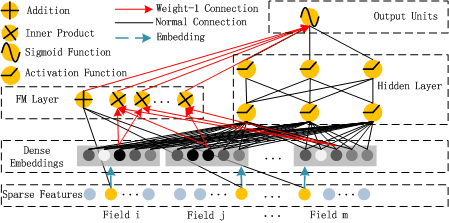
3.《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》FM的深度学习版本
这个模型基于wide & deep做了改进,首先模型包括FM和DNN部分,是个并联结构,FM和DNN共享相同的输入(embedding)。每个Field独立地embedding到相同的维度,大大减少了网络参数。Field到embedding层的映射向量恰好是FM层学习到的向量。
deep FM的优点: 1)不需要任何预训练 2)学习到了低维和高维特征交叉 3)一个特征embedding的共享策略来避免特征工程
基于内容的推荐
《Content-Based Recommendation Systems》 基于内容做推荐的综述文献。 这个文章是篇综述,没有很深的理论。文章分析了数据分为了结构化的数据和非结构化的数据,然后介绍了常见的机器学习算法,如决策树,线性模型,kNN方法,朴素贝叶斯等等方法。很适合作为推荐系统及其相关机器学习方法的入门教材。
基于DNN的推荐 《Deep Neural Networks for YouTube Recommendations》谷歌神作,字字珠玑 Youtube推荐系统的比较老的解决方案,使用候选集生成网络和排序网络两部分。特征是用户embedding和视频embedding,加入了视频的曝光时间等特征作为训练。本来听起来是简单的解决方案,其实里面把推荐系统工程化的问题都一一介绍了,让我们更清楚地知道,线下模型训练的过程和线上服务过程分别怎么做的,多分类问题怎么加速等。值得仔细思考里面的每一步做法的用意。
推荐系统架构:
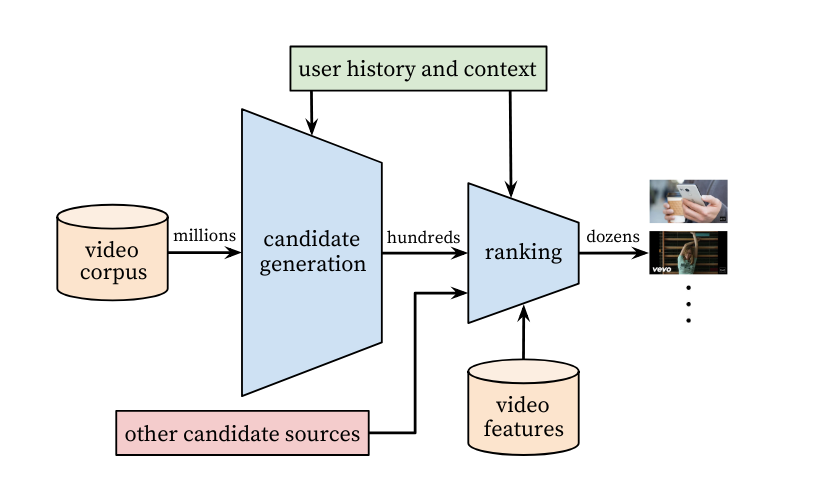
候选集生成网络: 
王喆对这篇文章进行了更详细的解读,并探讨了工程化的问题:https://zhuanlan.zhihu.com/p/52169807
基于标签的推荐
《Tag-Aware Recommender Systems: A State-of-the-art Survey》综述。 原本以为基于标签的推荐很简单,其实我错了,这个综述我就没看太懂。不过基于标签的推荐在实践里还是挺重要的,比如用户给主播打的标签可以用作推荐。
文章指出标签的作用: 1.反映用户的喜好 2.表达了物品的语义信息,来帮助评估潜在的用户质量 3.标签之间的重复出现的情况表现了用户的社区和物品的聚类情况。 因此,标签可以帮助解决冷启动问题。
1.基于网络的模型
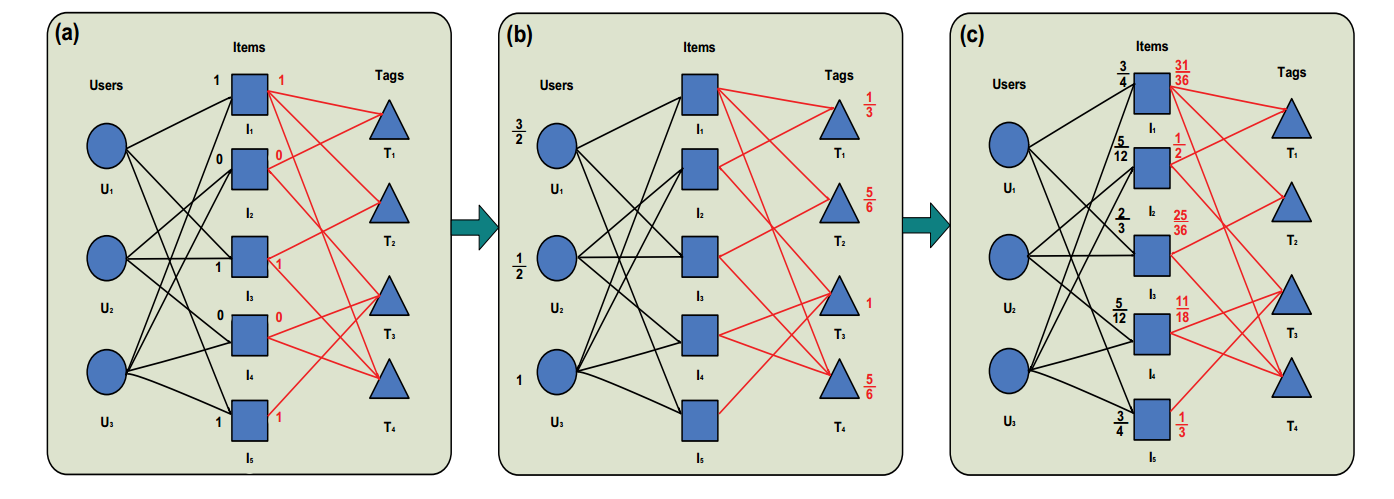
2.基于张量的模型
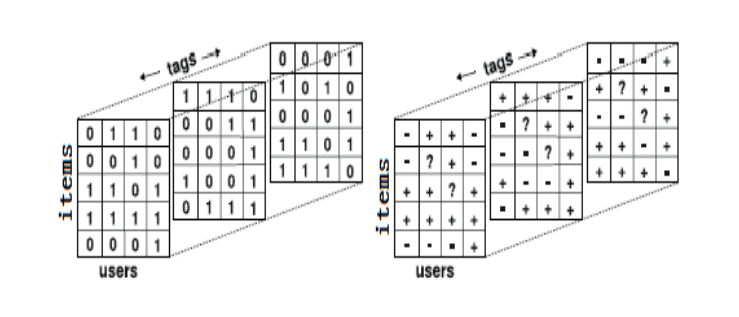
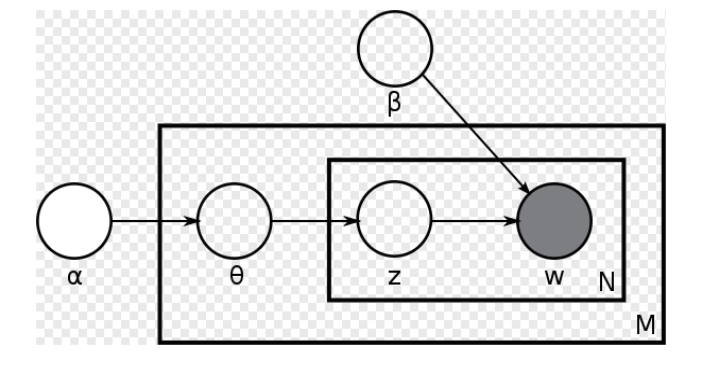
3.基于主题的模型(LDA)
基于自编码器
- 《AutoRec: Autoencoders Meet Collaborative Filtering》
- 《Training Deep AutoEncoders for Collaborative Filtering》NVIDIA的文章,偏向于工程实现
- 《Deep Collaborative Autoencoder for Recommender Systems:A Unified Framework for Explicit and Implicit Feedback》
- 《Collaborative Denoising Auto-Encoders for Top-N Recommender Systems》对推荐系统的归纳很好,公式很详细。
这几篇文章的思想基本一样,本质都是协同过滤。优化的目标在自编码器的基础上稍作修改,优化目标里只去优化有观测值的数据。
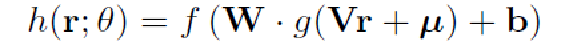
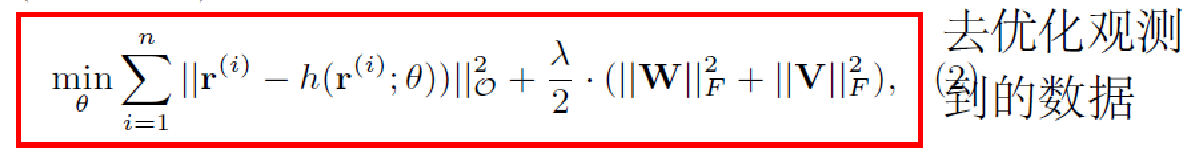
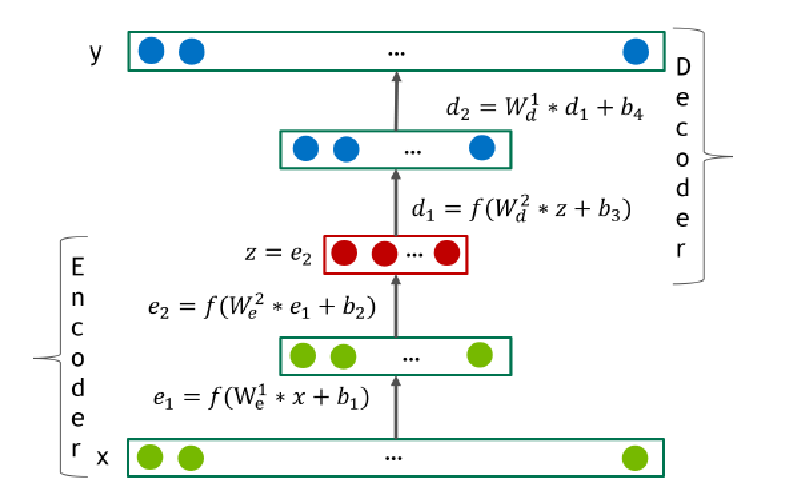
Item2Vec
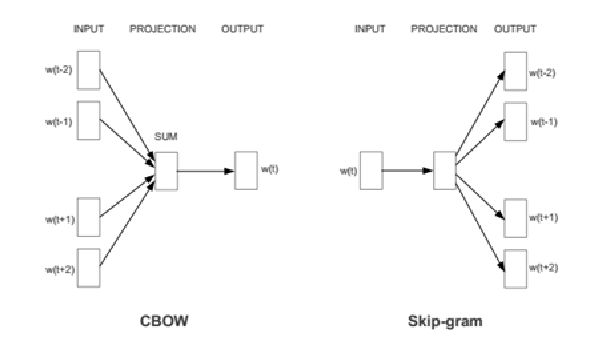
《Item2Vec: Neural Item Embedding for Collaborative Filtering》微软的开创性的论文,提出了Item2Vec,使用的是负采样的skip-gram 《Item2Vec-based Approach to a Recommender System》给出了开源实现,使用的是负采样的skip-gram 《From Word Embeddings to Item Recommendation》使用的社交网站历史check-in地点数据预测下次check-in的地点,分别用了skip-gram和CBOW 固定窗口的skip-gram的目标是最大化每个词预测上下文的总概率:
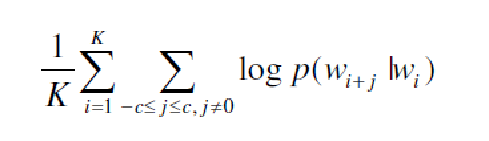
使用shuffle操作来让context包含每个句子中所有其他元素,这样就可以使用定长的窗口了。
上下文感知模型
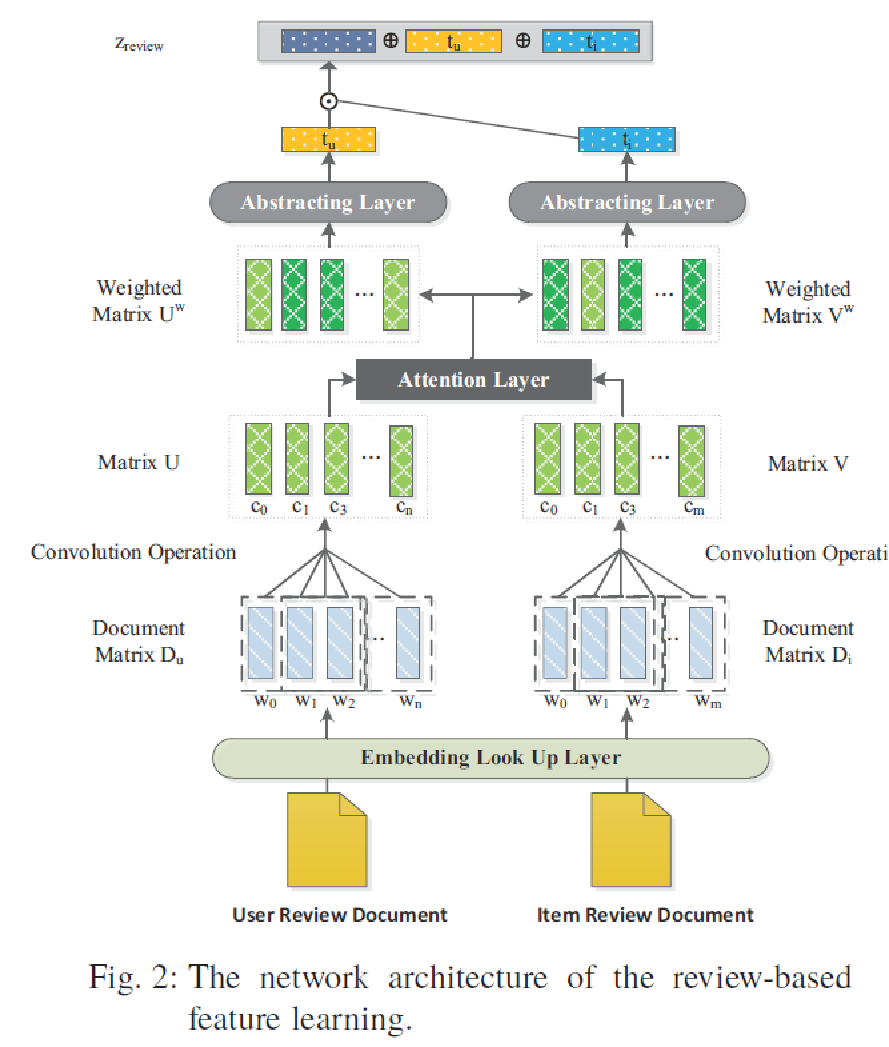
《A Context-Aware User-Item Representation Learning for Item Recommendation》 这个文章提出,以前的模型学到的用户和物品的隐层向量都是一个静态的,没有考虑到用户对物品的偏好。本文提出了上下文感知模型,使用用户的评论和物品总评论,通过用户-物品对进行CNN训练,加入了注意力层,摘要层,学习到的是用户和物品的联合表达。更倾向于自然语言处理的论文,和传统的推荐模型差距比较大。

基于视觉的推荐
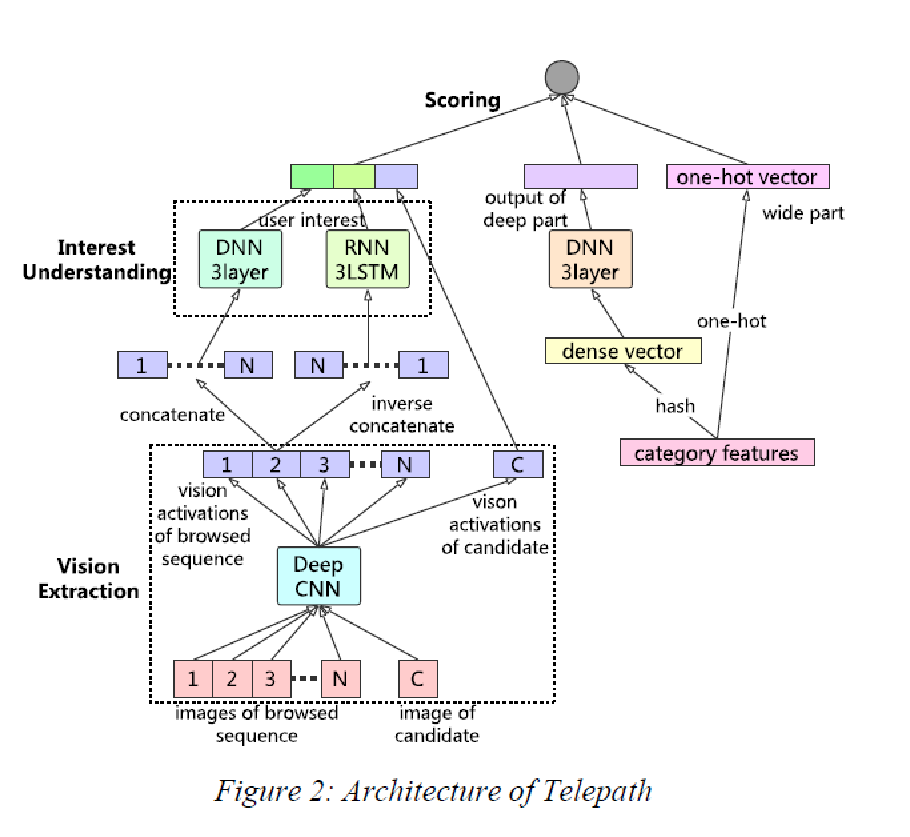
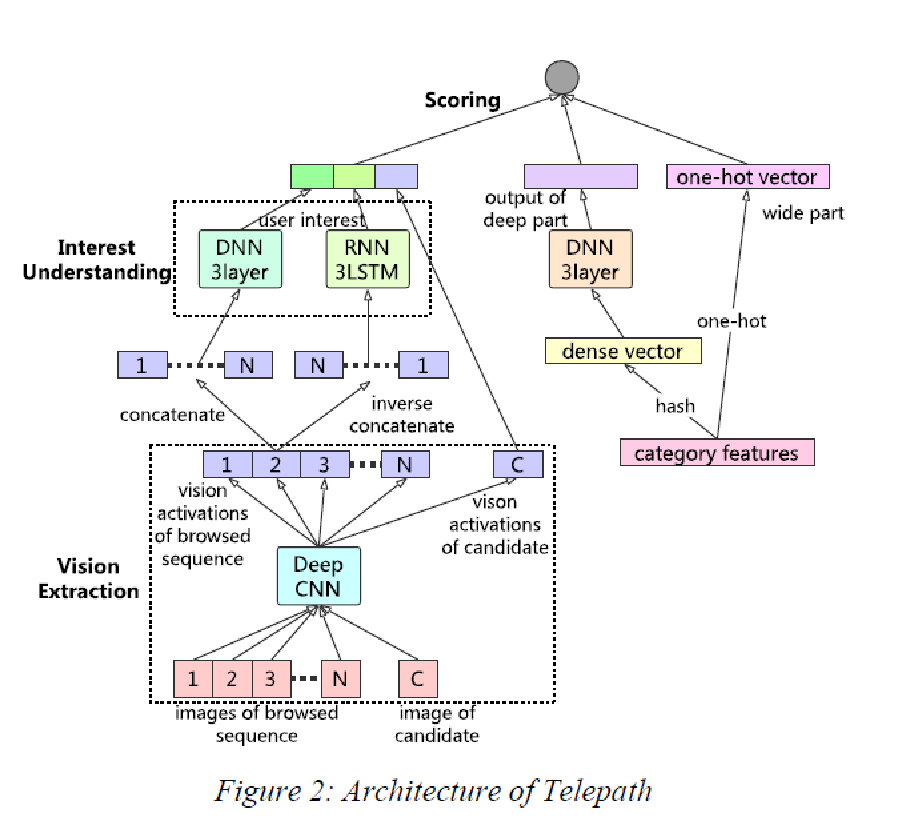
1.《Telepath: Understanding Users from a Human Vision Perspective in Large-Scale Recommender System》京东最近公开的推荐系统,通过研究商品的封面对人的影响进行推荐
这个文章参考大脑结构,我们把这个排序引擎分为三个组件:一个是视觉感知模块(Vision Extraction),它模拟人脑的视神经系统,提取商品的关键视觉信号并产生激活;另一个是兴趣理解模块(Interest Understanding),它模拟大脑皮层,根据视觉感知模块的激活神经元来理解用户的潜意识(决定用户的潜在兴趣)和表意识(决定用户的当前兴趣);此外,排序引擎还需要一个打分模块(Scoring),它模拟决策系统,计算商品和用户兴趣(包括潜在兴趣和当前兴趣)的匹配程度。兴趣理解模块收集到用户浏览序列的激活信号后,分别通过DNN和RNN,生成两路向量。RNN常用于序列分析,我们用来模拟用户的直接兴趣,DNN一般用以计算更广泛的关系,用来模拟用户的间接兴趣。最终,直接兴趣向量和间接兴趣向量和候选商品激活拼接在一起,送往打分模块。打分模块是个普通的DNN网络,我们用打分模块来拟合用户的点击/购买等行为。最终这些行为的影响通过loss回馈到整个Telepath模型中。在图右侧,还引入了类似Wide & Deep网络的结构,以增强整个模型的表达能力。
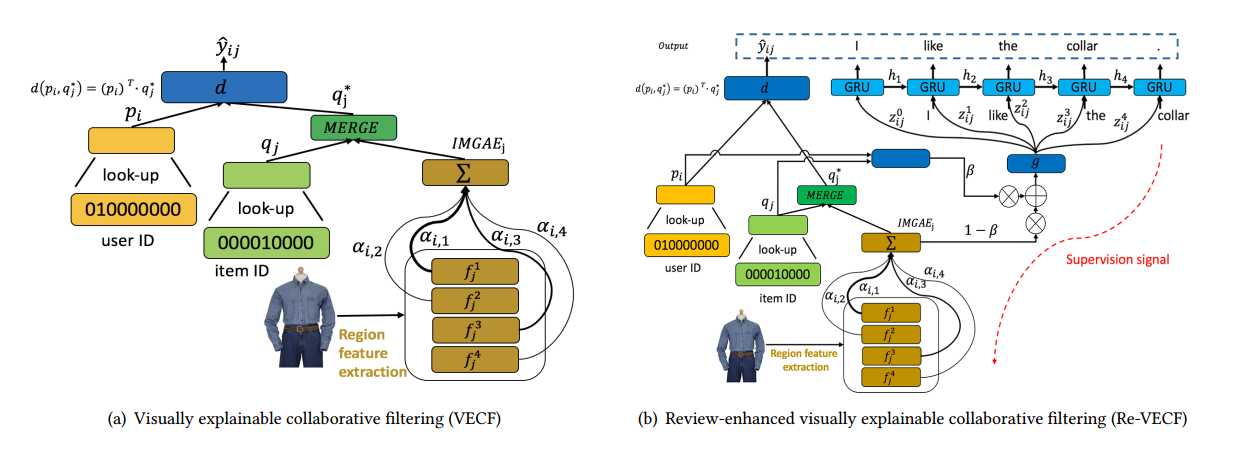
2.《Visually Explainable Recommendation》可视化地可解释推荐模型
这个文章放在基于视觉的推荐的原因是,比较新奇的地方在于提取了商品封面的特征,并融合到了推荐和推荐解释之中。本文的基础模型使用商品的封面通过预训练好的VGG网络转化为图像向量。对特征进行加权求和之后的结果与商品的向量merge,再与用户的向量内积求总的向量结果,把该结果进行和用户是否购买的真实数据求交叉熵,优化该Loss.文章指出该模型最后训练的结果可以用推荐,也可以用注意力权重来做推荐解释。
本文还提出了进一步的模型Re-VECF。该模型使用商品的用户评论结合图像、用户和商品作单词预测训练GRU。加入用户评论的好处是可以提高推荐的表现、文本评论可能隐含着用户对商品封面重要的偏好。该模型能更好的做出推荐结果和推荐解释。
基于RNN的推荐
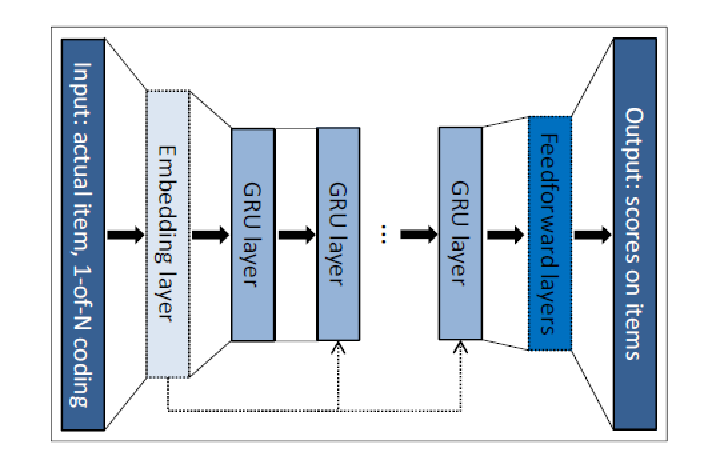
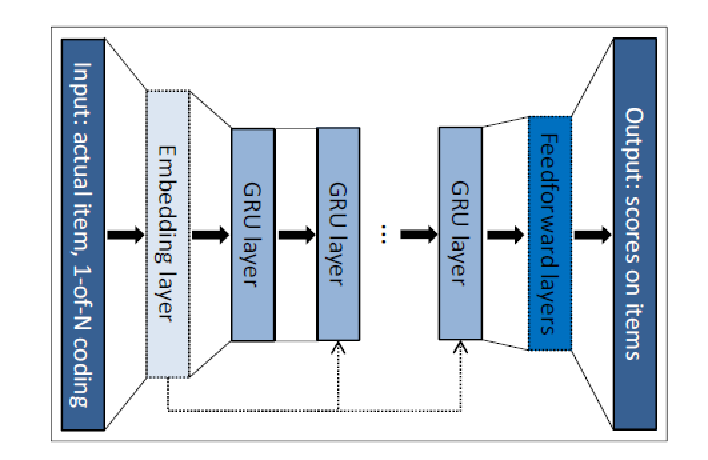
- 《Session-based Recommendations with Recurrent Neural Networks》 2016年的文章,GRU4Rec,使用每个会话中用户的行为记录进行训练。
- 《Recurrent Neural Networks with Top-k Gains for Session-based Recommendations》2018年的新文章,对上文进行了优化;原理相同的。
基于RNN的推荐也是源于一个朴素的假设:对于用户的行为序列,相邻的元素有着相近的含义。这种假设适合基于会话的推荐系统,如一次电子商务的会话,视频的浏览记录等。相对于电影推荐,基于会话的推荐系统跟看中短期内用户的行为。
论文想法在于把一个 session 点击一系列 item 的行为看做一个序列,用来训练一个 RNN 模型。在预测阶段,把 session 已知的点击序列作为输入,用 softmax 预测该session下一个最有可能点击的item。
这个文章里用的是GRU,目标是优化pair-wise rank loss。
有一个不错的论文解读文章:http://www.cnblogs.com/daniel-D/p/5602254.html
基于图的推荐
- 《Pixie: A System for Recommending 3+ Billion Items to 200+ Million Users in Real-Time》社交网站的图推荐,2017年
本文介绍了 Pinterest 的 Pixie 系统,主要针对他们开发的随机游走和剪枝算法,此外系统本身基于 Stanford Network Analysis Platform 实现。
基于树的推荐
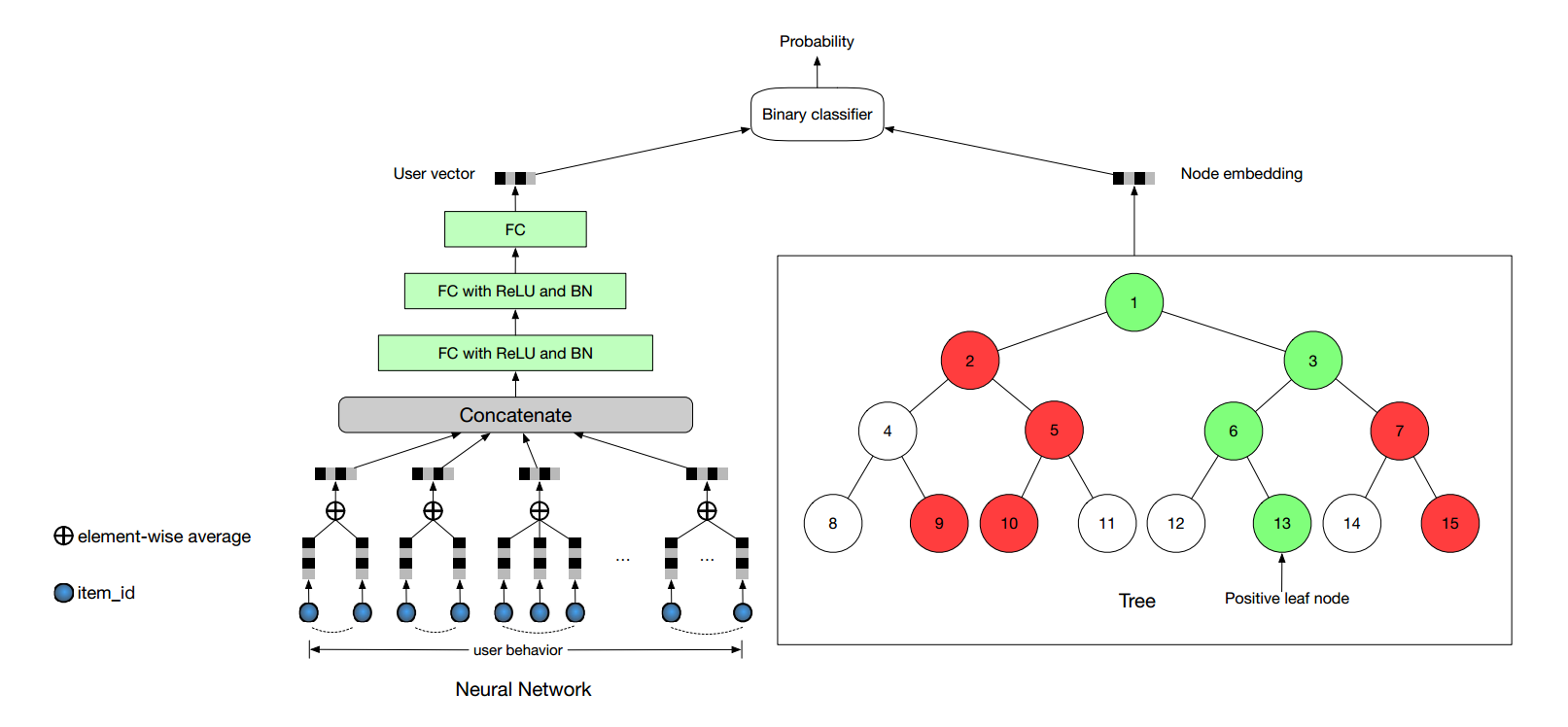
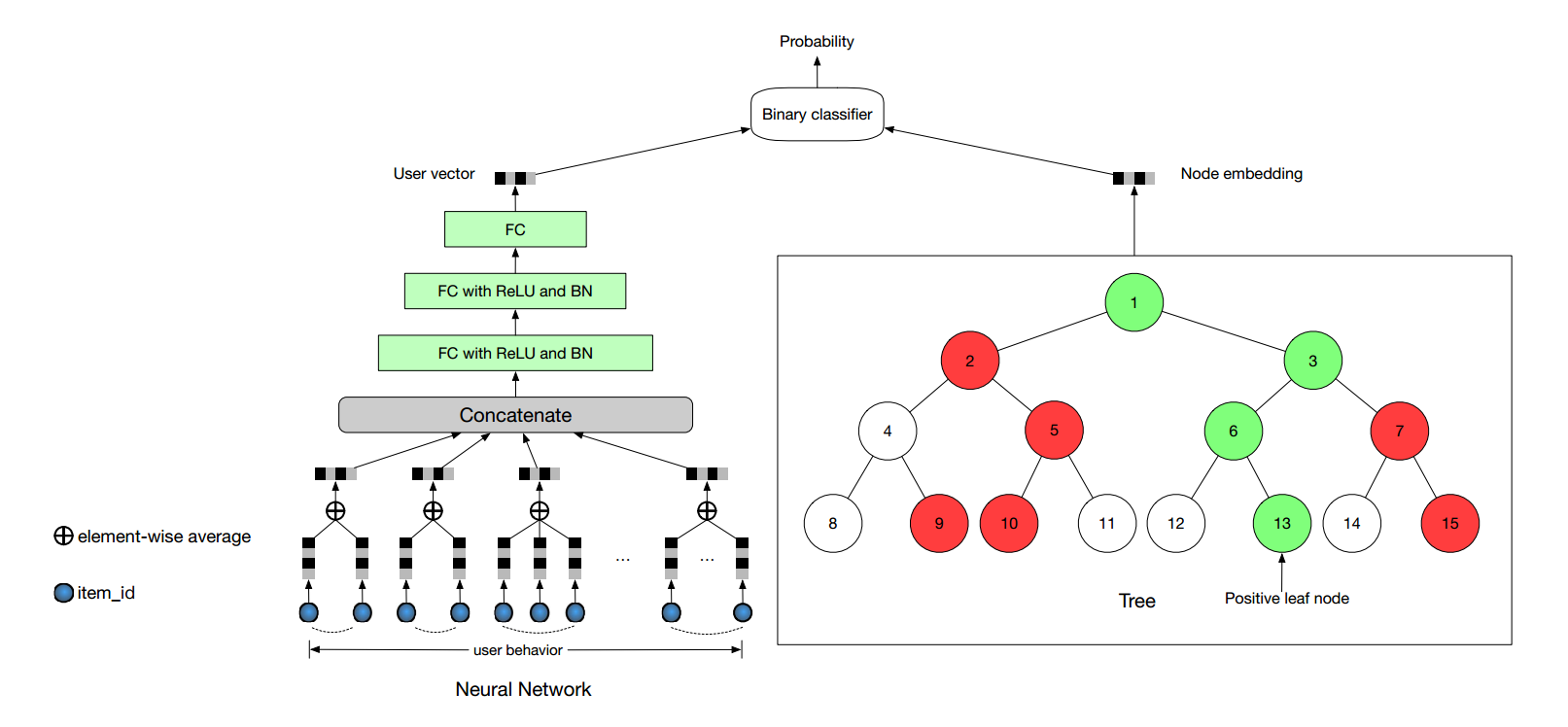
- 《Learning Tree-based Deep Model for Recommender Systems》淘宝的推荐系统,2018年最新发布
基于树的推荐是一种比较新奇的一种推荐算法,其设计的目的主要是解决淘宝的巨大的数据问题,给出了一种能线上服务的实时推荐系统的模型。此外,本文证明了此模型在MovieLens-20M和淘宝自己的用户数据上的准确、召回、新奇性都比传统方法好。
采用的数据是隐式反馈,本模型提供几百个候选集,然后实时预测系统会进行排序策略。
树的作用不仅仅是作为索引使用,更重要的是把海量的数据进行了层次化组织。训练过程是如果用户对某个物品感兴趣,那么最大化从该物品节点到根节点的每个节点的联合概率。该路径上的每个节点都和用户有相关性,树的结构从底向上表现出了用户物品的相似性和依赖性。
如下图所示,左侧的三层全连接学习到用户的向量表示,右侧的树结构学到了节点的表示,最后通过二分类来训练出用户是否对该节点感兴趣。训练的损失函数是最小化一个用户对每个采样了的节点的交叉熵。(树结构类似于Hierarchical softmax,也同样使用了负采样等。)
公司的推荐系统的发展历程
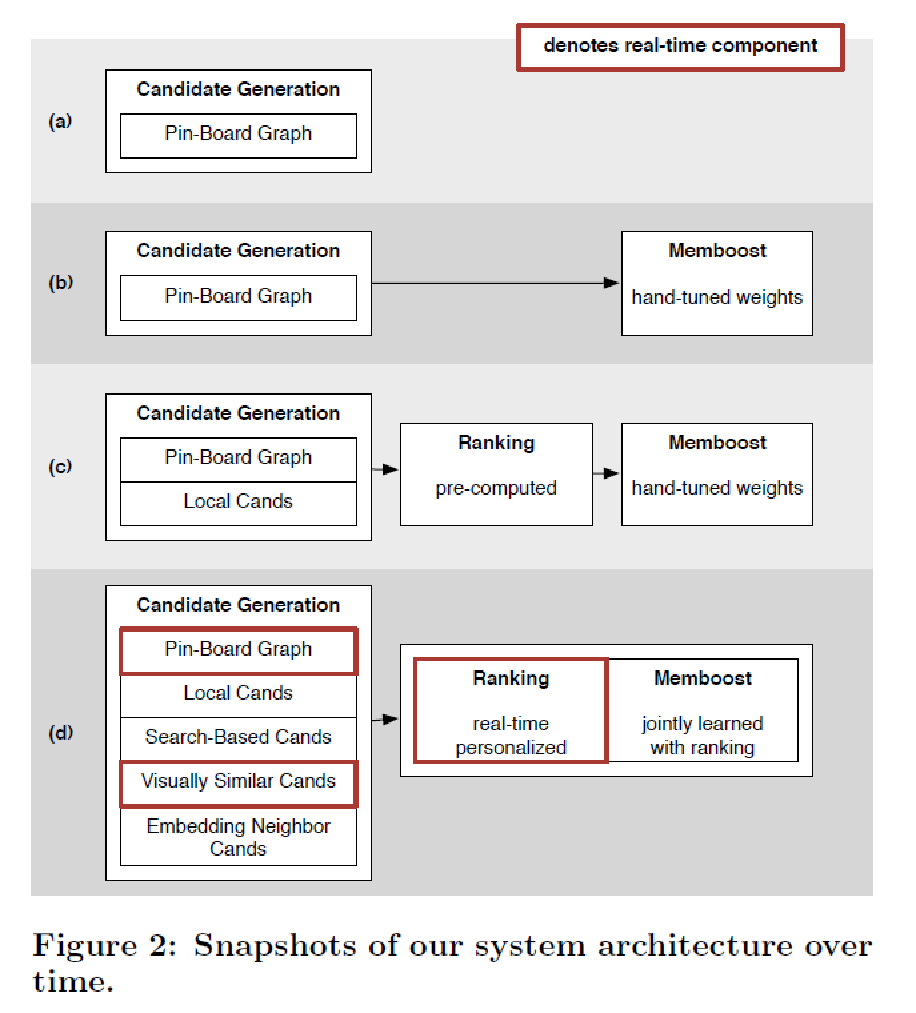
- 《Related Pins at Pinterest: The Evolution of a Real-World Recommender System》Pinterest的推荐系统发展历程
这个推荐系统主要用到的是随机游走的图算法,Pin2Vec,Learning to Rank等方法。只介绍了思想,没有公式和算法。可以直接看解读:http://blog.csdn.net/smartcat2010/article/details/75194918
- 2013年的时候,推荐系统主要基于Pin-Board的关联图,两个Pin的相关性与他们在同一个Board中出现的概率成正比。
- 在有了最基本的推荐系统后,对Related Pin的排序进行了初步的手调,手调信号包括但不局限于相同Board中出现的概率,两个Pin之间的主题相似度,描述相似度,以及click over expected clicks得分。
- 渐渐地,发现单一的推荐算法很难满足产品想要优化的不同目标,所以引入了针对不同产品需求生成的候选集(Local Cands),将排序分为两部分,机器粗排和手调。
- 最后,引入了更多的候选集,并且提高了排序部分的性能,用机器学习实现了实时的个性化推荐排序。
数据集 《Indian Regional Movie Dataset for Recommender Systems》提供了印度本土的电影观看数据集
参考资料
- 『我爱机器学习』FM、FFM与DeepFM
- Factorization Machines 学习笔记
转载自https://github.com/fuxuemingzhu/Summary-of-Recommender-System-Papers
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







