 资源下载
资源下载



【毕业设计】基于深度学习的视觉问答

文件列表(压缩包大小 2.36M)
免费
概述
研究目的
对于视觉问答(VQA)的研究具有深刻的学术意义和广阔的应用前景。目前,视觉问答模型性能提升的重点在于图像特征的提取,文本特征的提取,attention权重的计算和图像特征与文本特征融合的方式这4个方面。本文主要针对attention权重的计算和图像特征与文本特征融合这两个方面,以及其他细节方面的地方相对于前人的模型做出了改进。本文的主要工作在于本文使用open-ended模式,答案的准确率采用分数累积,而不是一般的多项选择。本文采用CSF模块(包括CSF_A和CSF_B)不仅对spatial-wise进行了权重计算,还对channel-wise进行了权重计算。本文采用MFB模块和ResNet152 FC层之前的tensor来结合LSTM的输出来计算每个区域的权重,而不是直接把image feature和question feature结合本文采用SigMoid来计算最后的分布,而不是一般的softmax(实验部分会有对比两者的差异)。
研究方法
数据集&数据预处理
本文使用VQA2.0数据集来训练和测试模型 VQA2.0的图像集由来自MS-COCO数据集的约200,000幅图像组成,每个图像3个问题,每个问题10个答案 使用开放式(OE)模式来回答问题,开放式模式要求模型更具图片和问题直接提供答案,而不是从十几个选项中选出对的那个,但是由于开放式(OE)的答案非常难以评估,答案存在歧义性和同义性问题,所以本文首先对答案和问题进行了预处理,使得问题和答案更易于训练和评估。 问题预处理:替换、分词、截断&补全(14 word)、index 根据每个问题中对应答案出现的次数来计算每个答案的分数,然后将每个问题的答案形成一个一维的分布(候选答案总数为3097)
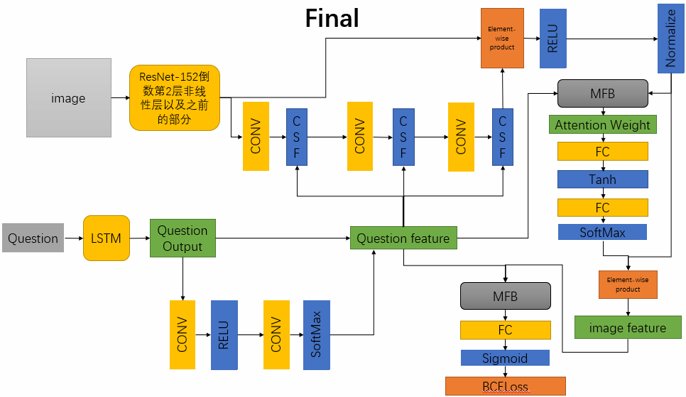
总体模型
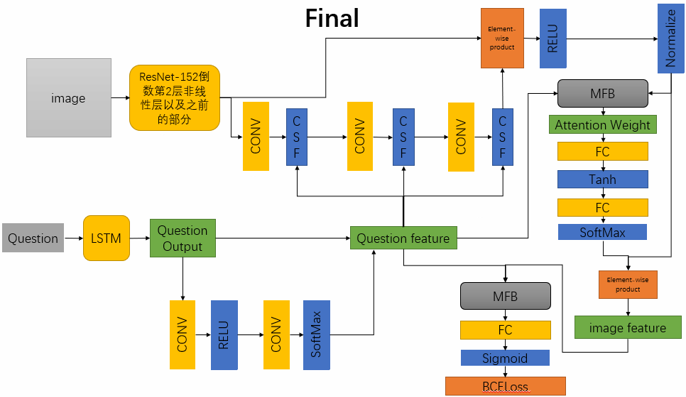
MFH模块
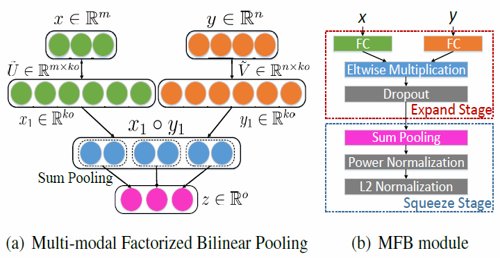
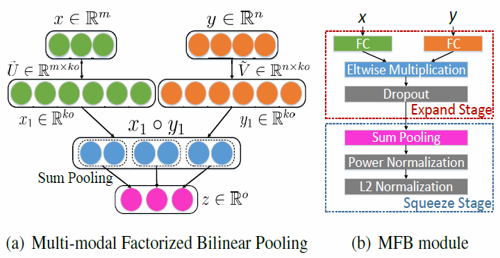 MFB模块用到了bilinear pooling技术,但和一般的bilinear pooling不同,MFB用Factorized Bilinear Pooling来减少参数个数和计算复杂度,从而来大大降低内存消耗量和运行时间,在结合𝑎_𝑖𝑚𝑔和𝑏_𝑞𝑢𝑒之后我得到了最终的融合向量c=SumPooling(𝑈 ̃^𝑇 𝑎_𝑖𝑚𝑔 ° 𝑉 ̃^𝑇 𝑏_𝑞𝑢𝑒, 𝑘),其中k为人为定义的超参,k越大就是复杂度越高但表示能力越强
MFB模块用到了bilinear pooling技术,但和一般的bilinear pooling不同,MFB用Factorized Bilinear Pooling来减少参数个数和计算复杂度,从而来大大降低内存消耗量和运行时间,在结合𝑎_𝑖𝑚𝑔和𝑏_𝑞𝑢𝑒之后我得到了最终的融合向量c=SumPooling(𝑈 ̃^𝑇 𝑎_𝑖𝑚𝑔 ° 𝑉 ̃^𝑇 𝑏_𝑞𝑢𝑒, 𝑘),其中k为人为定义的超参,k越大就是复杂度越高但表示能力越强
CSF子模块
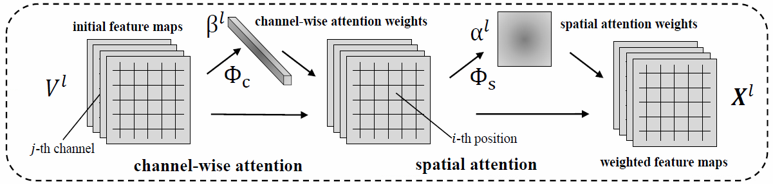 文本创建了两种CSF模块,分别为CSF_A和CSF_B,两者差别仅在于计算attention权重的函数不同,其流程都与上图一样,本文进行了相关对照试验并对使用不同模块的总体模型的准确率进行了比较,最后采取了CSF_A模块
文本创建了两种CSF模块,分别为CSF_A和CSF_B,两者差别仅在于计算attention权重的函数不同,其流程都与上图一样,本文进行了相关对照试验并对使用不同模块的总体模型的准确率进行了比较,最后采取了CSF_A模块

研究结论
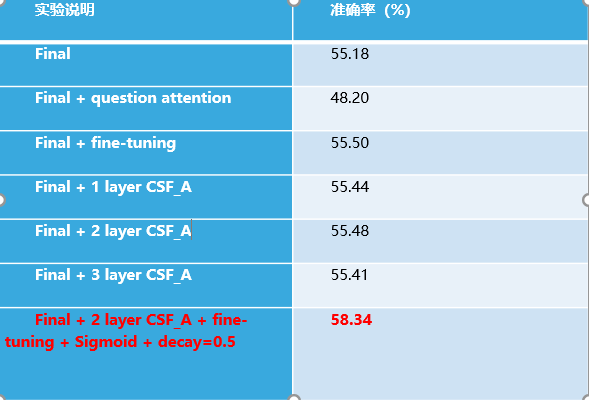
在经过大量试验之后,本文得到了较好的结果58.34%,虽然相对于目前世界上对于视觉问答的研究的最高的准确率62%还有较大的差距(这里不包括ensemble模型等用来刷分的技巧),但是任然相对于Baseline的53.71%有了较大的提高
 转载自:https://github.com/kyocen/Graduation-Design-VQA-based-on-deep-learning
转载自:https://github.com/kyocen/Graduation-Design-VQA-based-on-deep-learning
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







