 资源下载
资源下载

RoBERTa中文预训练模型

文件列表(压缩包大小 272.82K)
免费
概述
中文预训练RoBERTa模型
RoBERTa是BERT的改进版,通过改进训练任务和数据生成方式、训练更久、使用更大批次、使用更多数据等获得了State of The Art的效果;可以用Bert直接加载。
本项目是用TensorFlow实现了在大规模中文上RoBERTa的预训练,也会提供PyTorch的预训练模型和加载方式。
中文预训练RoBERTa模型-下载
6层RoBERTa体验版
- RoBERTa-zh-Layer6: Google Drive 或 百度网盘,TensorFlow版本,Bert 直接加载, 大小为200M
推荐 RoBERTa-zh-Large 通过验证
RoBERTa-zh-Large: Google Drive 或 百度网盘 ,TensorFlow版本,Bert 直接加载
RoBERTa-zh-Large: Google Drive 或 百度网盘 ,PyTorch版本,Bert的PyTorch版直接加载
RoBERTa 24/12层版训练数据:30G原始文本,近3亿个句子,100亿个中文字(token),产生了2.5亿个训练数据(instance);覆盖新闻、社区问答、多个百科数据等;
本项目与中文预训练24层XLNet模型 XLNet_zh项目,使用相同的训练数据。
RoBERTa_zh_L12: Google Drive 或 百度网盘 TensorFlow版本,Bert 直接加载
RoBERTa_zh_L12: Google Drive 或百度网盘 PyTorch版本,Bert的PyTorch版直接加载
Roberta_l24_zh_base TensorFlow版本,Bert 直接加载
24层base版训练数据:10G文本,包含新闻、社区问答、多个百科数据等
什么是RoBERTa:
一种强大的用于预训练自然语言处理(NLP)系统的优化方法,改进了Transformers或BERT的双向编码器表示形式,这是Google在2018年发布的自监督方法。
RoBERTa在广泛使用的NLP基准通用语言理解评估(GLUE)上产生最先进的结果。 该模型在MNLI,QNLI,RTE,STS-B和RACE任务上提供了最先进的性能,并在GLUE基准上提供了可观的性能改进。 RoBERTa得分88.5,在GLUE排行榜上排名第一,与之前的XLNet-Large的表现相当。
效果测试与对比 Performance
互联网新闻情感分析:CCF-Sentiment-Analysis
| 模型 | 线上F1 |
|---|---|
| BERT | 80.3 |
| Bert-wwm-ext | 80.5 |
| XLNet | 79.6 |
| Roberta-mid | 80.5 |
| Roberta-large (max_seq_length=512, split_num=1) | 81.25 |
注:数据来源于guoday的开源项目;数据集和任务介绍见:CCF互联网新闻情感分析
自然语言推断:XNLI
| 模型 | 开发集 | 测试集 |
|---|---|---|
| BERT | 77.8 (77.4) | 77.8 (77.5) |
| ERNIE | 79.7 (79.4) | 78.6 (78.2) |
| BERT-wwm | 79.0 (78.4) | 78.2 (78.0) |
| BERT-wwm-ext | 79.4 (78.6) | 78.7 (78.3) |
| XLNet | 79.2 | 78.7 |
| RoBERTa-zh-base | 79.8 | 78.8 |
| RoBERTa-zh-Large | 80.2 (80.0) | 79.9 (79.5) |
注:RoBERTa_l24_zh,只跑了两次,Performance可能还会提升;
BERT-wwm-ext来自于这里;XLNet来自于这里; RoBERTa-zh-base,指12层RoBERTa中文模型
问题匹配语任务:LCQMC(Sentence Pair Matching)
| 模型 | 开发集(Dev) | 测试集(Test) |
|---|---|---|
| BERT | 89.4(88.4) | 86.9(86.4) |
| ERNIE | 89.8 (89.6) | 87.2 (87.0) |
| BERT-wwm | 89.4 (89.2) | 87.0 (86.8) |
| BERT-wwm-ext | - | - |
| RoBERTa-zh-base | 88.7 | 87.0 |
| RoBERTa-zh-Large | 89.9(89.6) | 87.2(86.7) |
| RoBERTa-zh-Large(20w_steps) | 89.7 | 87.0 |
注:RoBERTa_l24_zh,只跑了两次,Performance可能还会提升。保持训练轮次和论文一致:
阅读理解测试
目前阅读理解类问题bert和roberta最优参数均为epoch2, batch=32, lr=3e-5, warmup=0.1
cmrc2018(阅读理解)
| models | DEV |
|---|---|
| sibert_base | F1:87.521(88.628) EM:67.381(69.152) |
| sialbert_middle | F1:87.6956(87.878) EM:67.897(68.624) |
| 哈工大讯飞 roberta_wwm_ext_base | F1:87.521(88.628) EM:67.381(69.152) |
| brightmart roberta_middle | F1:86.841(87.242) EM:67.195(68.313) |
| brightmart roberta_large | F1:88.608(89.431) EM:69.935(72.538) |
DRCD(阅读理解)
| models | DEV |
|---|---|
| siBert_base | F1:93.343(93.524) EM:87.968(88.28) |
| siALBert_middle | F1:93.865(93.975) EM:88.723(88.961) |
| 哈工大讯飞 roberta_wwm_ext_base | F1:94.257(94.48) EM:89.291(89.642) |
| brightmart roberta_large | F1:94.933(95.057) EM:90.113(90.238) |
CJRC(带有yes,no,unkown的阅读理解)
| models | DEV |
|---|---|
| siBert_base | F1:80.714(81.14) EM:64.44(65.04) |
| siALBert_middle | F1:80.9838(81.299) EM:63.796(64.202) |
| 哈工大讯飞 roberta_wwm_ext_base | F1:81.510(81.684) EM:64.924(65.574) |
| brightmart roberta_large | F1:80.16(80.475) EM:65.249(66.133) |
阅读理解测试对比数据来源bert_cn_finetune
? 处地方,将会很快更新到具体的值
RoBERTa中文版 Chinese Version
本项目所指的中文预训练RoBERTa模型只指按照RoBERTa论文主要精神训练的模型。包括:
数据生成方式和任务改进:取消下一个句子预测,并且数据连续从一个文档中获得(见:Model Input Format and Next Sentence Prediction,DOC-SENTENCES)
更大更多样性的数据:使用30G中文训练,包含3亿个句子,100亿个字(即token)。由新闻、社区讨论、多个百科,包罗万象,覆盖数十万个主题,所以数据具有多样性(为了更有多样性,可以可以加入网络书籍、小说、故事类文学、微博等)。
训练更久:总共训练了近20万,总共见过近16亿个训练数据(instance); 在Cloud TPU v3-256 上训练了24小时,相当于在TPU v3-8(128G显存)上需要训练一个月。
更大批次:使用了超大(8k)的批次batch size。
调整优化器等超参数。
除以上外,本项目中文版,使用了全词mask(whole word mask)。在全词Mask中,如果一个完整的词的部分WordPiece子词被mask,则同属该词的其他部分也会被mask,即全词Mask。
本项目中并没有直接实现dynamic mask。通过复制一个训练样本得到多份数据,每份数据使用不同mask,并加大复制的分数,可间接得到dynamic mask效果。
使用说明 Instructions for Use
当前本项目是使用sequence length为256训练的,所以可能对长度在这个范围内的效果不错;如果你的任务的输入比较长(如序列长度为512),或许效果有影响。
有同学结合滑动窗口的形式,将序列做拆分,还是得到了比较好的效果,
中文全词遮蔽 Whole Word Mask
| 说明 | 样例 |
|---|---|
| 原始文本 | 使用语言模型来预测下一个词的probability。 |
| 分词文本 | 使用 语言 模型 来 预测 下 一个 词 的 probability 。 |
| 原始Mask输入 | 使 用 语 言 [MASK] 型 来 [MASK] 测 下 一 个 词 的 pro [MASK] ##lity 。 |
| 全词Mask输入 | 使 用 语 言 [MASK] [MASK] 来 [MASK] [MASK] 下 一 个 词 的 [MASK] [MASK] [MASK] 。 |
模型加载(以Sentence Pair Matching即句子对任务,LCQMC为例)
下载LCQMC数据集,包含训练、验证和测试集,训练集包含24万口语化描述的中文句子对,标签为1或0。1为句子语义相似,0为语义不相似。
tensorFlow版本:
1、复制本项目: git clone https://github.com/brightmart/roberta_zh
2、进到项目(roberta_zh)中。
假设你将RoBERTa预训练模型下载并解压到该改项目的roberta_zh_large目录,即roberta_zh/roberta_zh_large
运行命令:
export BERT_BASE_DIR=./roberta_zh_large
export MY_DATA_DIR=./data/lcqmc
python run_classifier.py \
--task_name=lcqmc_pair \
--do_train=true \
--do_eval=true \
--data_dir=$MY_DATA_DIR \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config_large.json \
--init_checkpoint=$BERT_BASE_DIR/roberta_zh_large_model.ckpt \
--max_seq_length=128 \
--train_batch_size=64 \
--learning_rate=2e-5 \
--num_train_epochs=3 \
--output_dir=./checkpoint_lcqmc
注:task_name为lcqmc_pair。这里已经在run_classifier.py中的添加一个processor,并加到processors中,用于指定做lcqmc任务,并加载训练和验证数据。
预训练 Pre-training
1) 预训练的数据 data of pre-training
你可以使用你的任务相关领域的数据来训练,也可以从通用的语料中筛选出一部分与你领域相关的数据做训练。
通用语料数据见nlp_chinese_corpus:包含多个拥有数千万句子的语料的数据集。
2) 生成预训练数据 generate data for pre-training
包括使用参照DOC-SENTENCES的形式,连续从一个文档中获得数据;以及做全词遮蔽(whole word mask)
shell脚本:批量将多个txt文本转化为tfrecord的数据。
如将第1到10个txt转化为tfrecords文件:
nohup bash create_pretrain_data.sh 1 10 &
注:在我们的实验中使用15%的比例做全词遮蔽,模型学习难度大、收敛困难,所以我们用了10%的比例;
3)运行预训练命令 pre-training 去掉next sentence prediction任务
export BERT_BASE_DIR=<path_of_robert_or_bert_model>
nohup python3 run_pretraining.py --input_file=./tf_records_all/tf*.tfrecord \
--output_dir=my_new_model_path --do_train=True --do_eval=True --bert_config_file=$BERT_BASE_DIR/bert_config.json \
--train_batch_size=8192 --max_seq_length=256 --max_predictions_per_seq=23 \
--num_train_steps=200000 --num_warmup_steps=10000 --learning_rate=1e-4 \
--save_checkpoints_steps=3000 --init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt &
注:如果你重头开始训练,可以不指定init_checkpoint;
如果你从现有的模型基础上训练,指定一下BERT_BASE_DIR的路径,并确保bert_config_file和init_checkpoint两个参数的值能对应到相应的文件上;
领域上的预训练,可以不用训练特别久。
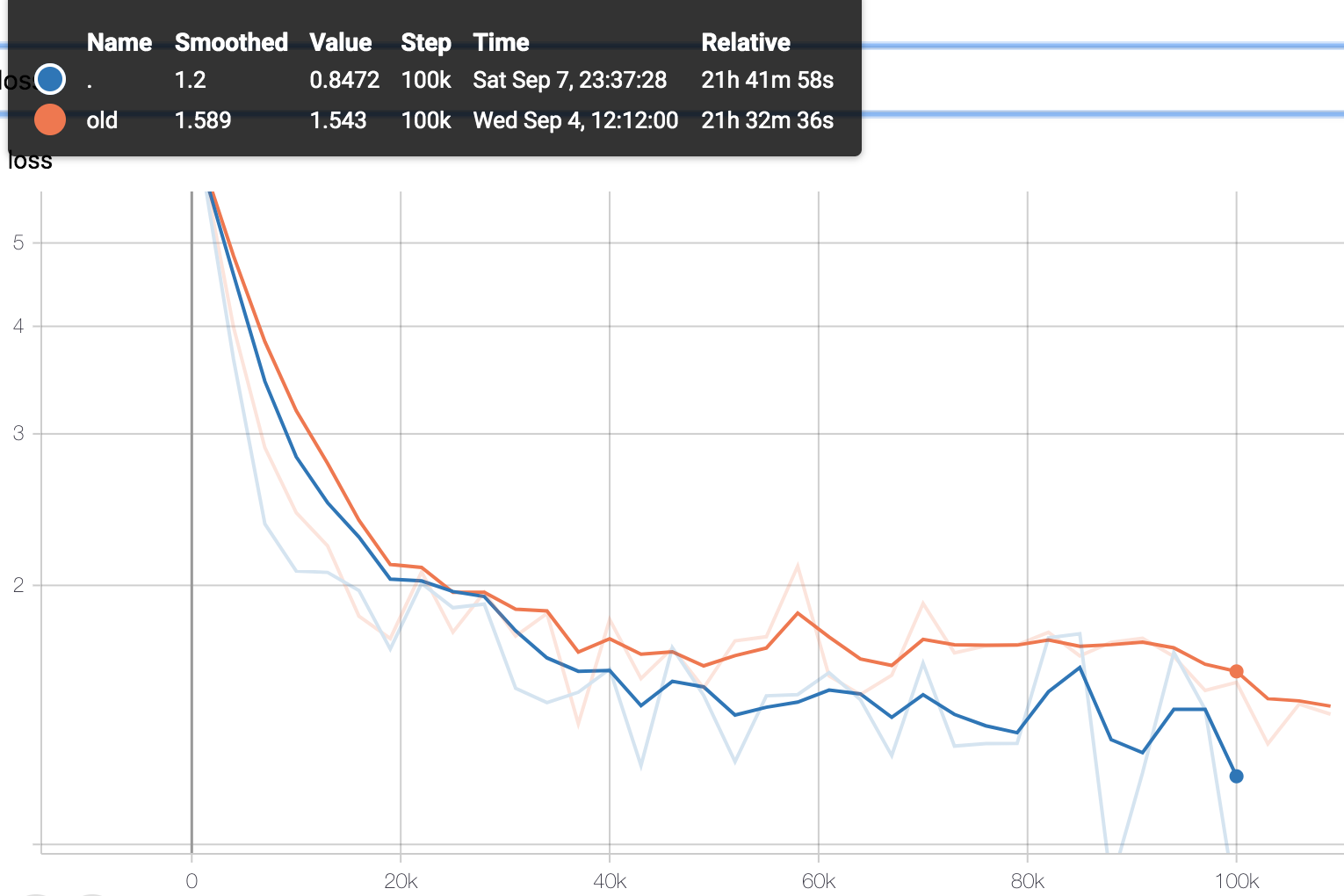
Learning Curve 学习曲线
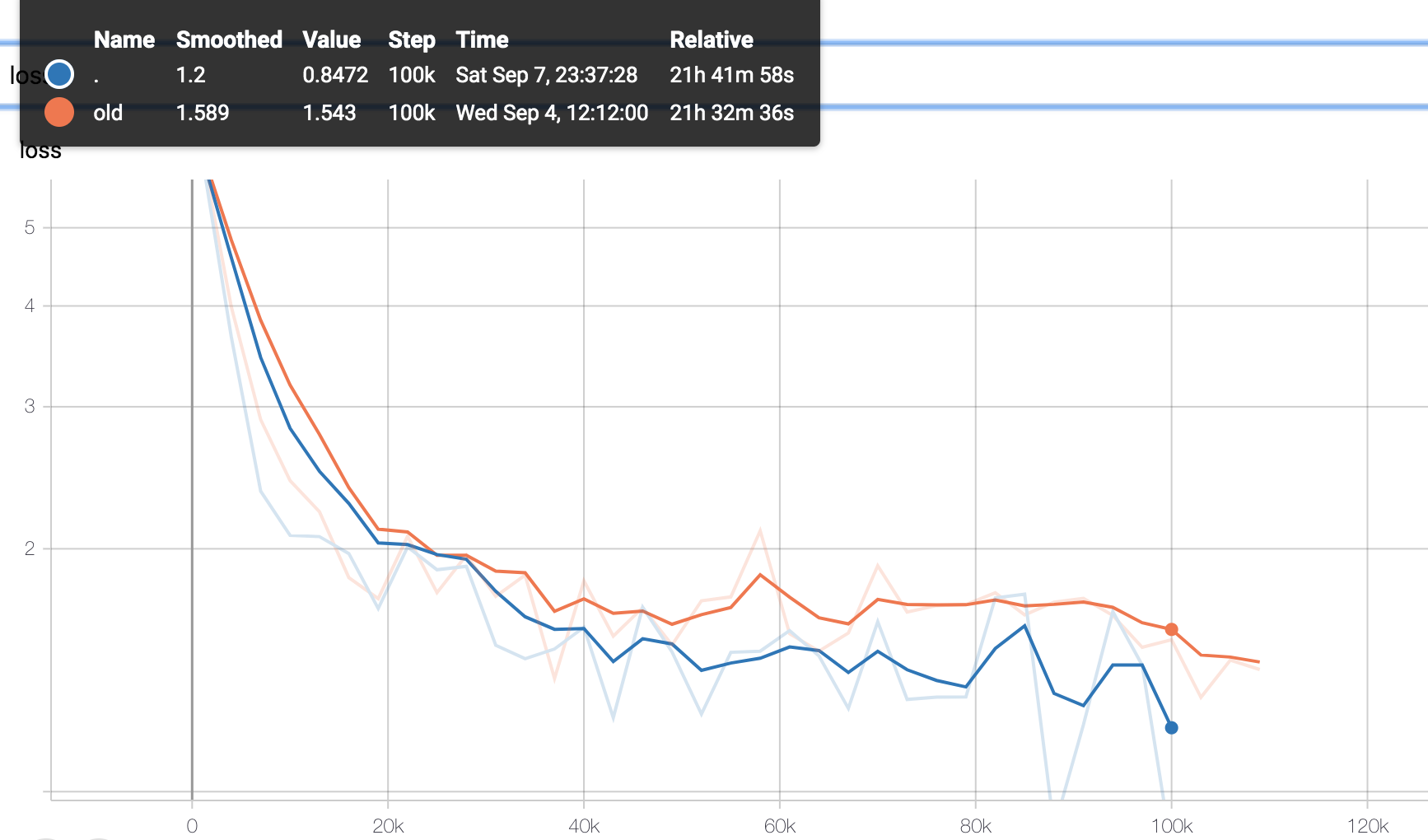
对显存的要求 Trade off between batch Size and sequence length
| System | Seq Length | Max Batch Size |
|---|---|---|
| RoBERTa-Base | 64 | 64 |
| ... | 128 | 32 |
| ... | 256 | 16 |
| ... | 320 | 14 |
| ... | 384 | 12 |
| ... | 512 | 6 |
| RoBERTa-Large | 64 | 12 |
| ... | 128 | 6 |
| ... | 256 | 2 |
| ... | 320 | 1 |
| ... | 384 | 0 |
| ... | 512 | 0 |
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







