 资源下载
资源下载


基于jstorm和flink的一体化实时计算服务平台

文件列表(压缩包大小 7.39M)
免费
概述
实时计算简介
随着互联网应用的迅速普及,需要进行处理的数据不仅在数量上迅速增长,在数据处理的时效性上也比之前有更加强烈的需求。在传统的数据处理流程中,一般是先收集数据并且将数据存储到数据存储介质中。然后当需要的时候通过对存储好的数据进行相关处理得到分析后的结果。这样的做法虽然能保证处理数据的准确性和完整性,但是却不能保证很好的时效性。导致人们无法及时的根据最新的数据分析结果做出正确的决策,从而数据的价值也随着时间的流逝而失去价值。
为了解决这些问题, 相对于保证数据分析的准确性,完整性而忽视时效性的传统批处理而言,产生了更加注重时效性的实时计算的概念。与一次性处理全部数据的批量计算不同,实时计算一般是对无限的数据流进行持续不断的连续运算,并对外输出运算结果供用户使用。
关于统一实时计算平台
目前常用的实时计算技术包括storm,jstorm,spark streaming和flink等,人们往往会根据自己业务需求的特点选择适合自己的实时计算引擎。而如何在公司内部部署和使用这些实时计算技术呢,下面以最常用的jstorm为例进行分析说明。
首先我们可以在一台机器上运行实时计算,也就相当于在一台机器上同时运行jstorm的 nimbus进程,supervisor进程以及具体任务的worker进程。这样做有很明显的缺点,包括不可扩展,性能受限于单台机器的资源,无法进行高可用等问题。
然后,为了解决以上的问题, 每个业务线可以选择自建独立的实时计算集群,这样的话虽然能在一定程度上克服单机运算的缺点,但同时也有不可忽视的问题,例如为了保证集群的高可用等,每个集群至少要有四台机器,包括一个nimbus主节点,一个nimbus从节点,以及两个supervisor节点。这样就需要预先准备大量机器资源,同时由于是每个业务线独立搭建各自的实时计算集群,也就无法保证建立统一的监控,报警等体系,并且每个集群都需要进行独立维护,因此维护难度大,需要投入很多的精力。
为了克服上述这些问题,需要一个统一的实时计算平台,来克服上述方案的诸多缺点。
实时计算平台
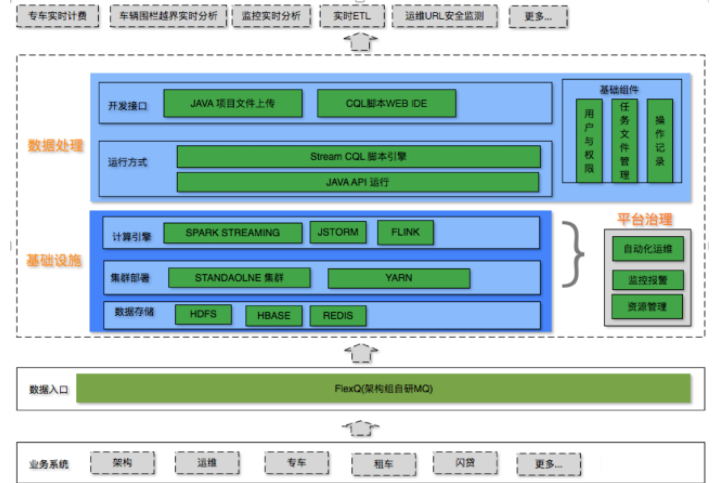
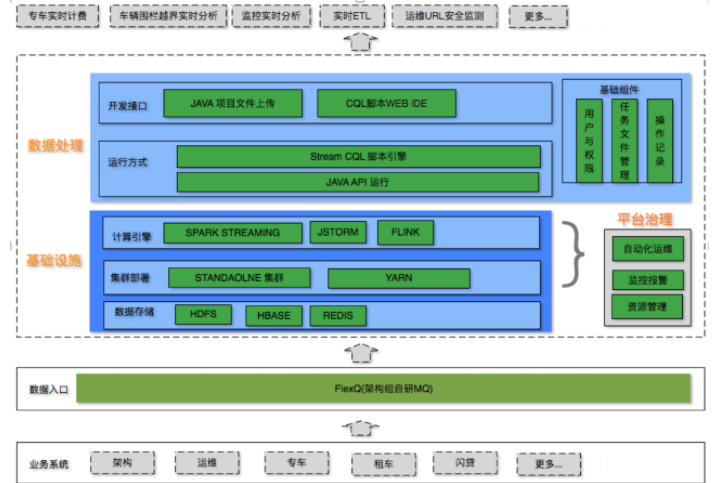 1.本项目实时计算集群是完全运行在YARN集群之上的,并且和离线计算集群是互相独立的两个YARN集群,独立构建流计算集群可以避免离线业务的干扰,并且与在线业务,MQ等相关组件在相同机房,延时低。
2、 平台统一监控所有实时任务的运行状态,在实时计算引擎本身的高可用基础之上,平台提供了自己的任务恢复策略,尽量保证实时任务的持续运行。
3、 平台支持基于华为开源的 StreamCQL 进行 JSTORM实时任务的编写和提交,并为了满足公司业务的需求进行了相关函数的扩展。
4、 平台支持基于 FLINK SQL 进行实时任务的编写,并进行了相关语法的扩展,例如可以用sql 表述 任务的输入source,输出sink,并提交任务,指定任务名等,这样用户就可以在平台的web 页面 完全用类似SQL的脚本语言描述实时任务,而无需再进行任务相关java代码的编写。
5、平台的JSTORM on YARN 使用的是自研的AM,并做了相关调整,支持在yarn集群上以每个实时任务独占一个JSTORM的集群方式进行运行,并解决了一个YARN集群上同时运行多个jstorm集群时可能会发生的问题,例如不同jstorm集群的nimbus端口冲突的问题。
6、 对于JSTORM任务,本项目在原生的API之上进行了封装,忽略了用户在API中设置的参数信息,而使用平台页面设置的参数进行设置。
7、 在公司内部针对公司独有的一些MQ等中间件提供了定制好的组件,方便用户使用
1.本项目实时计算集群是完全运行在YARN集群之上的,并且和离线计算集群是互相独立的两个YARN集群,独立构建流计算集群可以避免离线业务的干扰,并且与在线业务,MQ等相关组件在相同机房,延时低。
2、 平台统一监控所有实时任务的运行状态,在实时计算引擎本身的高可用基础之上,平台提供了自己的任务恢复策略,尽量保证实时任务的持续运行。
3、 平台支持基于华为开源的 StreamCQL 进行 JSTORM实时任务的编写和提交,并为了满足公司业务的需求进行了相关函数的扩展。
4、 平台支持基于 FLINK SQL 进行实时任务的编写,并进行了相关语法的扩展,例如可以用sql 表述 任务的输入source,输出sink,并提交任务,指定任务名等,这样用户就可以在平台的web 页面 完全用类似SQL的脚本语言描述实时任务,而无需再进行任务相关java代码的编写。
5、平台的JSTORM on YARN 使用的是自研的AM,并做了相关调整,支持在yarn集群上以每个实时任务独占一个JSTORM的集群方式进行运行,并解决了一个YARN集群上同时运行多个jstorm集群时可能会发生的问题,例如不同jstorm集群的nimbus端口冲突的问题。
6、 对于JSTORM任务,本项目在原生的API之上进行了封装,忽略了用户在API中设置的参数信息,而使用平台页面设置的参数进行设置。
7、 在公司内部针对公司独有的一些MQ等中间件提供了定制好的组件,方便用户使用
在以上基础之上,此实时计算平台提供了一系列方便用户使用的特性,使用户可以通过平台对其实时任务进行一站式管理,主要包括如下功能:
1、实时计算平台实现了客户可以完全通过web页面来管控自己的实时计算任务,例如创建任务,启动任务,停止任务等等。
2、通过平台的web页面上传实时任务文件或者编辑保存实时任务的类SQL脚本,在平台进行实时任务多版本的维护,支持实时任务的版本回滚。
3、在平台直接提交实时任务到集群进行运行,免去了提交任务客户机维护的烦恼。
4、在平台web页面提交任务时可以直接设置运行参数,并且随着数据量的变化可以直接在平台调整运行参数,避免任务的重新打包。
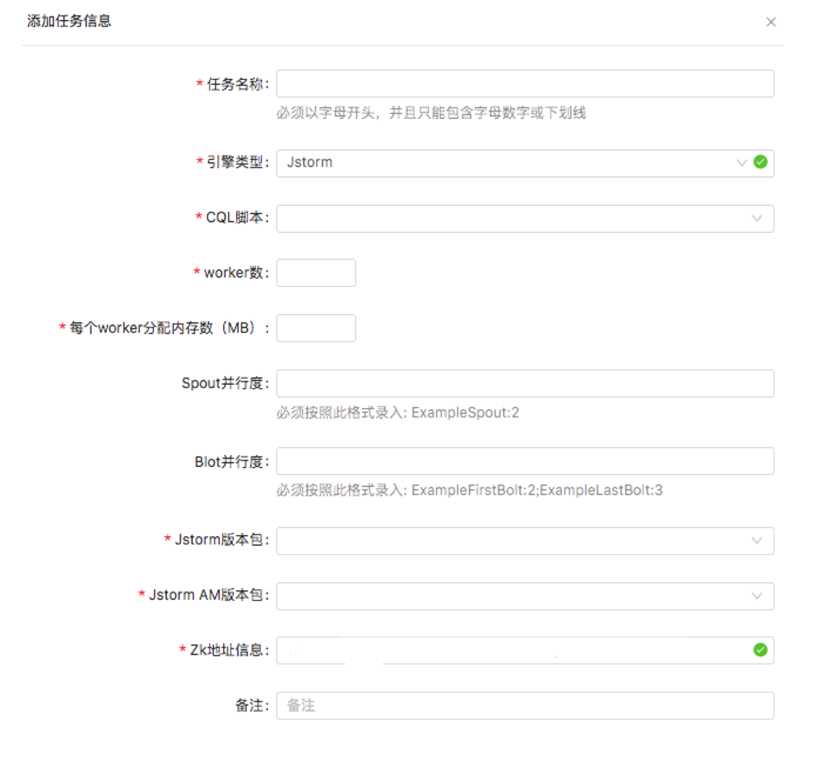
下图为提交任务的示意图:
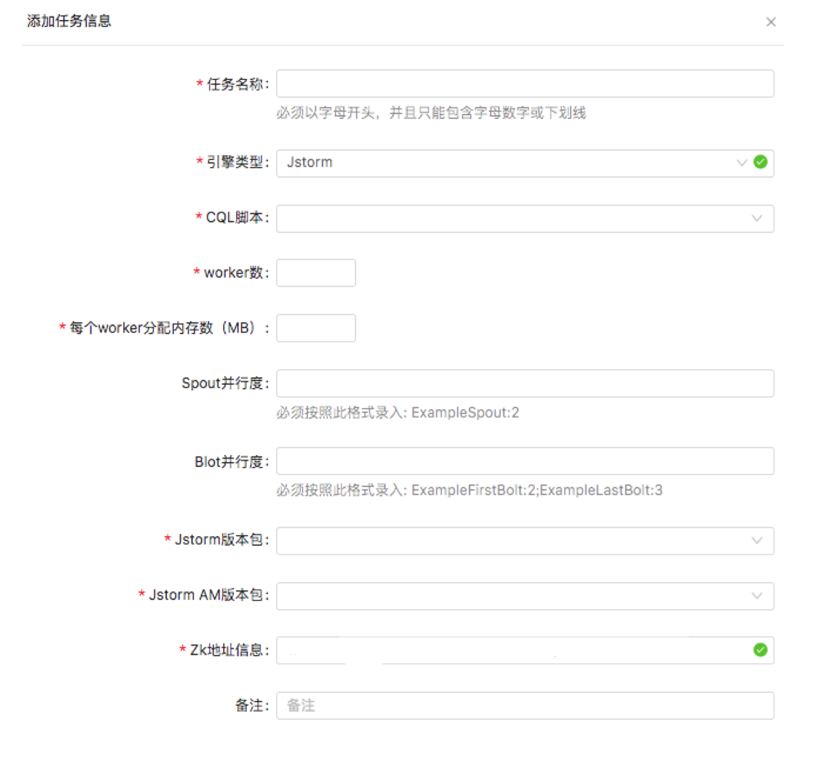 目前此实时计算平台为公司的多个业务场景提供服务,包括:
目前此实时计算平台为公司的多个业务场景提供服务,包括:
1、各种实时监控任务,目前例如公司内部关于 redis ,mq等中间件的监控等实时任务,这一部分任务有很大比例是基于 类sql脚本完成的 2、专车订单实时计费功能 3、租车车辆围栏相关实时计算任务
关于统一实时计算平台搭建的一些想法
1.划定平台的职责范围,利用有限的资源,集中资源做好核心功能. 2、 做好平台规划,能够清晰的知道平台的最终效果,设定里程碑,逐渐的实现平台。 3、 尽快的进行推广,接入各种实时任务,根据任务的实际运行情况,不断的进行调整和优化,避免闭门造车,完全实现后再推广。 4、目前的实时计算技术没有完美的银弹,所以实时计算平台设计上要能支持多种主要技术,例如JSTORM,SPARK,FLINK,针对任务的特点选用不同技术。 5、平台是根据需求不断演进的,目前此平台支持运行JSTORM和FLINK的任务,并且正在开发针对基于python脚本的Spark Streaming任务,方便不熟悉java的相关同学能够在平台上使用python脚本进行实时任务的开发。 6、底层技术的推广和研究不能懈怠,关于实时计算平台的搭建,不能仅仅停留在将已有的实时计算技术做个封装,对外提供一个web界面可以使用就叫完成了。在此基础之上,应该投入更多的精力对FLINK,JSTORM等相关技术进行深入研究,包括运行机制,参数优化,功能拓展与延伸,在保证任务稳定运行的基础之上能够开发出更多有用的特性。 7、应该投入更多的精力在平台推广上,平台搭建好之后不应该单纯的等用户来使用,而应该主动的了解业务场景,为其提出使用实时计算满足其业务场景的合理化建议,在和业务的合作中进一步对平台进行完善。
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







