 资源下载
资源下载



【Demo】基于Pytorch的中文语义相似度匹配模型

文件列表(压缩包大小 126.26K)
免费
概述
基于Pytorch的中文语义相似度匹配模型
运行环境:
python3.7 pytorch1.2 transformers2.5.1
数据集:
采用LCQMC数据(将一个句对进行分类,判断两个句子的语义是否相同(二分类任务)),因数据存在侵权嫌疑,故不提供下载,需要者可向官方提出数据申请http://icrc.hitsz.edu.cn/info/1037/1146.htm ,并将数据解压到data文件夹即可。
模型评测指标为:ACC,AUC以及预测总共耗时。
Embeding:
本项目输入都统一采用分字策略,故通过维基百科中文语料,训练了字向量作为Embeding嵌入。训练语料、向量模型以及词表,可通过百度网盘下载。 链接:https://pan.baidu.com/s/1qByw67GdFSj0Vt03GSF0qg 提取码:s830
模型文件:
本项目训练的模型文件(不一定最优,可通过超参继续调优),也可通过网盘下载。 链接:https://pan.baidu.com/s/1qByw67GdFSj0Vt03GSF0qg 提取码:s830
测试集结果对比:
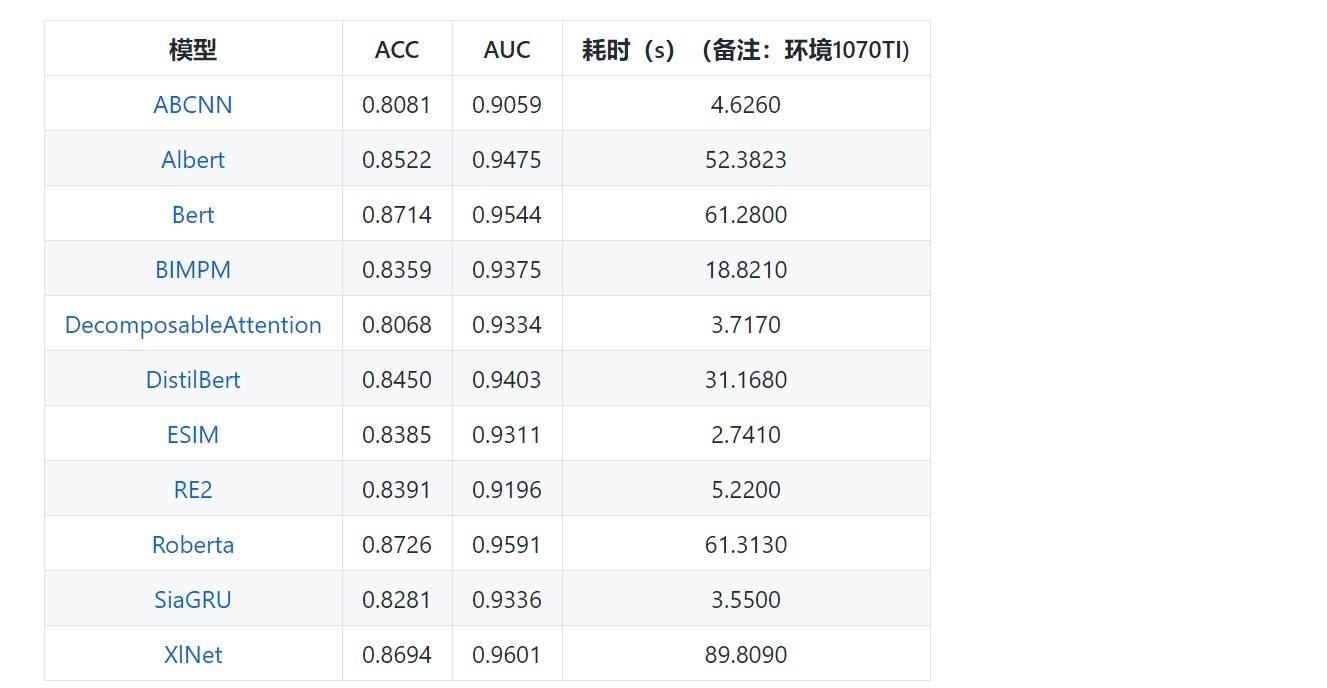
部分模型,借鉴了 https://github.com/alibaba-edu/simple-effective-text-matching-pytorch https://github.com/pengshuang/Text-Similarity 等项目。
理工酷提示:
如果遇到文件不能下载或其他产品问题,请添加管理员微信:ligongku001,并备注:产品反馈

评论(0)

0/250







