 资源下载
资源下载

当神经网络模型结构变得更深来提高性能和准确性同时降低计算成本时,Inception net是CNN分类器中一个里程碑意义的出现。另一方面,Inception net是经过精心设计的,在速度和准确性方面,它使用了很多技巧来提高性能。它是2014年ImageNet大规模视觉识别竞赛的冠军,与ZFNet(2013年的获奖者),AlexNet(2012年的获奖者)相比有显着进步,并且与VGGNet(2014年季军)。
诸如VGGNet之类的更深的CNN模型面临的主要问题是:
尽管以前的网络(例如VGG)在ImageNet数据集上实现了显着的准确性,但是由于其很深的体系结构,部署此类模型的计算量很大。
非常深的网络易于过度拟合。通过整个网络传递更新也很困难。
Inception net中的重要概念
在深入探讨Inception Net模型之前,必须了解Inception net中使用的重要概念:
1 X 1卷积:1×1卷积将具有所有相应通道的输入像素映射到输出像素。 1×1卷积用作降维模块,在一定程度上减少计算量。
- 例如,我们需要执行5×5卷积而不使用1×1卷积,如下所示:

运算次数为(14×14×48)×(5×5×480)= 112.9M
- 使用1×1卷积:
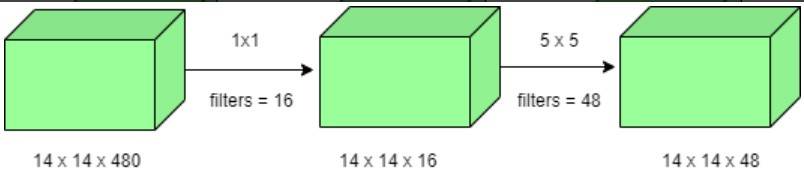
1×1卷积的运算次数=(14×14×16)×(1×1×480)= 1.5M 5×5卷积的运算次数=(14×14×48)×(5×5×16)= 3.8M 加法后我们得到:1.5M + 3.8M = 5.3M
以上结果远远小于112.9M!因此,1×1卷积可以帮助减小模型大小,也可以在一定会程度上帮助减少过拟合问题。
尺寸减小的初始模型:

深度卷积网络在计算量非常大。但是,通过引入1 x 1卷积可以大大降低计算成本。在此,通过在3×3和5×5卷积之前添加额外的1×1卷积来限制输入通道的数量。请注意,在最大池化层之后而不是之前引入1×1卷积。最后,将网络中的所有通道串联在一起,即(28 x 28 x(64 + 128 + 32 + 32))= 28 x 28 x 256。
Inception网络的GoogLeNet架构
该架构共有22层。使用降维的初始模块,构建了神经网络架构,这就是GoogLeNet(Inception v1)。 GoogLeNet具有9个线性匹配的初始模块,它深22层(包括池化层在内为27层)。在结构的最后,全连接层被全局平均池替换,该池计算每个特征图的平均值,这大大减少了参数的总数。
因此,Inception Net相对CNN模型先前版本是比较成功的。它在ImageNet上达到了top-5的精度,在不影响速度和精度的情况下,很大程度上降低了计算成本。
参考:https://www.geeksforgeeks.org/ml-inception-network-v1/?ref=lbp








